| Oracle® TimesTen In-Memory Database Reference 11g Release 2 (11.2.2) E21643-24 |
|
|
View PDF |
| Oracle® TimesTen In-Memory Database Reference 11g Release 2 (11.2.2) E21643-24 |
|
|
View PDF |
This chapter provides reference information for TimesTen utilities, beginning with the following introductory sections:
The options for TimesTen utilities are generally not case sensitive, except for single character options. You can use -connstr or -connStr interchangeably. However -v and -V are each unique options.
All utilities return 0 for success and nonzero if an error occurs.
Note:
The utility name and options listed in this chapter are case-insensitive. They appear in mixed case to make the examples and syntax descriptions easier to read.The following sections describe the authentication and authorization required for utilities:
All utilities that require a password prompt for one.
If a UID connection attribute is given but no PWD attribute is given, either through a connection string or in the ODBCINI file for the specified DSN, TimesTen prompts for a password. When explicitly prompted, input is not displayed on the command line.
Generally, when no UID connection attribute is given, the UID is assumed to be the user name identified by the operating system, and TimesTen does not prompt for a password.
When a utility accepts a DSN, connection string or database path as a parameter, specify the value at the end of the command line.
Note:
For security reasons, we do not recommend setting a a value forPWD on the command line.Certain TimesTen command-line utilities require privileges. Each utility in this chapter describes the privilege required for execution. You may receive a "database not loaded" error if you try to execute any utility with a user other than the instance administrator and the database is not loaded into memory. In this case, TimesTen cannot determine the privileges of the user.
Thus any utilities requiring privileges have to be run either as the instance administrator or executed while the database is loaded.
Enables you to:
Specify policies to automatically or manually load and unload databases from RAM.
Specify policies to automatically or manually start and stop replication agents for specified databases.
Start and stop TimesTen cache agents for caching data from Oracle database tables. The cache agent is a process that handles Oracle database access on behalf of a TimesTen database. It also handles the aging and autorefresh of the cache groups in the TimesTen database. Before using any cache features, you must start the cache agent. Cache options require that you specify a value for the OracleNetServiceName in the DSN.
This utility requires no privileges to query the database.
Replication options require the ADMIN privilege.
Cache options require the CACHE_MANAGER privilege.
All other options require the ADMIN privilege.
ttAdmin {-h | -help | -?}
ttAdmin {-V | -version}
ttAdmin [-ramPolicy always|manual|inUse [-ramGrace secs] ]
[-ramLoad] [-ramUnload]
[-autoreload | -noautoreload]
[-repPolicy always|manual|norestart]
[-reqpQueryThresholdGet]
[-reqpQueryThresholdSet seconds]
[-repStart | -repStop]
[[-cacheUidGet] |
[-cacheUidPwdSet -cacheUid uid [-cachePwd pwd]] |
[-cachePolicy always|manual|norestart] |
[-cacheStart] |
[-cacheStop [-stopTimeout seconds]]]
[-query]
{-connStr connection_string | DSN}
ttAdmin has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be administered. |
-h -help
|
Prints a usage message and exits. |
-autoreload | -noautoreload |
if set to -noautoreload, TimesTen does not automatically reload the database after an invalidation.
If set to |
-cachePolicy |
Defines the policy used to determine when the cache agent for the database should run.
This option requires |
-cacheStart |
Starts a cache agent for the database. This option requires CACHE_MANAGER privileges. |
-cacheStop |
Stops a cache agent for the database. You should not shut down the cache agent immediately after dropping or altering a cache group. Instead, wait for at least two minutes. Otherwise, the cache agent may not get a chance to clean up the Oracle database objects that were used by the AUTOREFRESH feature. This option requires CACHE_MANAGER privileges. |
-cachePwd |
The password associated with the cache administration user ID that manages autorefresh cache groups and asynchronous writethrough cache groups. The cache administration user has extended privileges. See "Grant privileges to the Oracle database users" in the Oracle TimesTen Application-Tier Database Cache User's Guide for more details. This option requires CACHE_MANAGER privileges. |
-cacheUid |
The cache administration user ID. The cache administration user manages autorefresh cache groups and asynchronous writethrough cache groups. The cache administration user has extended privileges. This option requires CACHE_MANAGER privileges.
See "Grant privileges to the Oracle database users" in the Oracle TimesTen Application-Tier Database Cache User's Guide for more details. |
-cacheUidGet |
Gets the current cache administration user ID for the specified database. This option requires CACHE_MANAGER privileges. |
-cacheUidPwdSet |
Sets the cache administration user name and password for the specified database. This option requires CACHE_MANAGER privileges. Must be set with the -cacheUid and -cachePwd options. Some things to consider are:
|
-query |
Displays a summary of the policy settings for the named database. |
-ramGrace secs |
Only effective if -ramPolicy is inUse. If nonzero, the database is kept in RAM for secs seconds before being unloaded after the last application disconnects from the database. |
-ramLoad |
Valid only when -ramPolicy is set to manual. Causes the database to be loaded into RAM. |
-ramPolicy policy |
Defines the policy used to determine when the database is loaded into system RAM.
This option requires |
-ramUnload |
Valid only when -ramPolicy is set to manual. Causes the database to be unloaded from RAM. |
-repPolicy |
Defines the policy used to determine when the replication agent starts.
This option requires |
-repQueryThresholdGet |
Returns the number of seconds that a query can be executed by the replication agent before TimesTen writes a warning to the support log and throws an SNMP trap.
A value of This option requires |
-repQueryThresholdSet |
This option specifies the number of seconds that a query can be executed by the replication agent before TimesTen writes a warning to the support log and throws an SNMP trap.
The specified value takes effect the next time the replication agent starts. The query threshold for the replication agent applies to SQL execution on detail tables of materialized views, The value must be greater than or equal to Default is This option requires |
-repStart |
Starts the database's replication agent. |
-repStop |
Stops the database's replication agent. |
-stopTimeout seconds |
Specifies that the TimesTen daemon should stop the cache agent if it does not stop within seconds.
If set to This option requires |
-V | -version |
Prints the release number of ttAdmin and exits. |
Some very performance sensitive applications use a database referred to by DSN SalesData. So that applications do not have to wait for the database to be loaded from disk into RAM, this database must always remain in RAM. To keep the database in memory, use:
ttAdmin -ramPolicy always SalesData
The SalesData database is normally always resident in RAM. However, it is not being used at all today and should be loaded only when applications are connected to it. To change the RAM policy, use:
ttAdmin -ramPolicy inUse SalesData
To manually control whether the SalesData database is loaded into RAM and to load it now, use the following.
ttAdmin -ramPolicy manual -ramLoad SalesData
To manually unload the SalesData database from RAM, thus preventing any new applications from connecting to the database, use:
ttAdmin -ramPolicy manual -ramUnload SalesData
A database referred to by DSN History is not always in use. Permanently loading it into RAM unnecessarily uses memory. This database is idle for long periods, but when it is in use multiple users connect to it in rapid succession. To improve performance, it may be best to keep the database in RAM when applications are connected to it and to keep it in RAM for 5 minutes (300 seconds) after the last user disconnects. With this RAM policy, the database remains in RAM if applications are connected to the database. To set this policy, use:
ttAdmin -ramPolicy inUse -ramGrace 300 History
A database referred to by DSN SalesData contains data cached from an Oracle database. Use the following ttAdmin command to start the cache agent for the SalesData DSN:
ttAdmin -cacheStart SalesData
You can also use the -cachePolicy option to ask the TimesTen data manager daemon to start the cache agent every time the data manager itself is started. Use:
ttAdmin -cachePolicy always SalesData
To turn off the automatic start of cache agent, use:
ttAdmin -cachePolicy manual SalesData
To set the cache administration user ID and password, you can use the -cacheUidPwdSet flag with the -cacheUid and -cachePwd options. For example, if the cache administration user ID and password on the database SalesData should be scott and tiger respectively, use:
ttAdmin -cacheUidPwdSet -cacheUid scott -cachPwd tiger SalesData
To get the current cache administration user ID for the SalesData DSN, use:
ttAdmin -cacheUidGet SalesData
ttAdmin displays the following output:
Cache User Id: scott RAM Residence Policy: inUse Replication Agent Policy: manual Replication Manually Started: False Cache Agent Policy: manual Cache Agent Manually Started: False
If TimesTen is installed as a user instance, and the user attempts to start the cache agent for a database with a relative path, TimesTen looks for the database relative to where it is running, and fails. Therefore, a relative path should not be used in this scenario. For example, on Windows, if you have specified the path for the database as DataStore=./dsn1 and attempt to start the cache agent with the command ttAdmin -cacheStart dsn1, the cache agent does not start because it looks for the database in install_dir\srv\dsn1. For UNIX it looks in a directory in /var/TimesTen/instance/.
When using autorefresh (automatic propagation from an Oracle database to a TimesTen database) or asynchronous writethrough cache groups, you must specify the cache administration user ID and password. This user account performs autorefresh and asynchronous writethrough operations.
To load data from an Oracle database, the TimesTen cache agent must be running. This requires that the ORACLE_HOME environment variable be set to the path of the Oracle installation. See the Oracle TimesTen Application-Tier Database Cache User's Guide for more details. For details on other environment variables that you may want to set, see "Environment variables" in Oracle TimesTen In-Memory Database Installation Guide.
This utility is supported only for TimesTen Data Manager DSNs. It is not supported for TimesTen Client DSNs.
If ttAdmin is used with -repStart and it does not find a replication definition, the replication agent is not started and ttAdmin prints out an error message. For example:
$ ttAdmin -repstart repl1 *** [TimesTen][TimesTen 11.2.2.0.0 ODBC Driver][TimesTen]TT8191: This store (repl1 on my_host) is not involved in a replication scheme -- file "eeProc.c", lineno 11016, procedure "RepAdmin()" *** ODBC Error = S1000, TimesTen Error = 8191
If ttAdmin is used with the -ramPolicy always option, a persistent system connection is created on the database.
The only -ramPolicy value supported for temporary databases is the -ramPolicy manual option with the -ramLoad option specified at the same time.
If ttAdmin is used with -repPolicy manual (the default) or -repPolicy always, then the -ramPolicy always option should also be used. This ensures that the replication agent begins recovery after a failure as quickly as possible.
On UNIX systems, use this utility to move databases from a TimesTen instance to a new TimesTen instance that is of the same major release, but of a different minor release. For example, you can move files from TimesTen 11.2.2.5.0 to TimesTen 11.2.2.6.0.
Note:
A major release refers to the first three digits of the release number. A minor release refers to the last two digits of the release number.This utility is useful for testing a minor release of Times with an existing database. You can install the new release of TimesTen and move one or more databases to the new release without uninstalling the old TimesTen release.
You must run the ttAdoptStores utility from the destination instance.
This utility must be run by the TimesTen instance administrator. The instance administrator must be the same user for both the old and new TimesTen instance.
ttadoptstores {-h | -help | -?}
ttadoptstores {-V | -version}
ttadoptstores [-quiet] -dspath path
ttadoptstores [-quiet] -instpath path
ttAdoptStores has the options:
| Option | Description |
|---|---|
-dspath path |
Adopts a single database. The path argument must be the path to the database files (without any file extensions). |
-h
|
Prints a usage message and exits. |
-instpath path |
Adopts all databases for an instance. The path argument must be the path to the daemon working directory (infodir).
If any databases are in use, the utility fails without making any modifications. No new connections to any database are allowed in the source instance until the entire operation has completed. |
-quiet |
Do not return verbose messages. |
-V | -version |
Prints the release number of ttAdoptStores and exits. |
To adopt the database /my/data/stores/ds, use:
ttadoptstores -dspath /my/data/stores/ds
To adopt all the databases in the directory /opt/TimesTen/ instance1, use:
ttadoptstores -instpath /opt/TimesTen/instance1
You cannot adopt temporary databases.
If an instance being adopted is part of a replication scheme, port numbers must match on each side of the replication scheme, unless a port number was specified as the value of the -remoteDaemonPort option during a ttRepAdmin -duplicate operation. Generally, all instances involved in the replication scheme must be updated at the same time.
This utility does not copy any sys.odbc.ini entries. You must move these files manually.
Creates a backup copy of a database that can be restored at a later time using the ttRestore utility. For an overview of the TimesTen backup and restore facility, see "Migration, Backup, and Restoration" in Oracle TimesTen In-Memory Database Installation Guide.
This utility requires the ADMIN privilege.
If authentication information is not supplied in the connection string or DSN, this utility prompts for a user ID and password before continuing.
ttBackup {-h | -help | -?}
ttBackup {-V | -version}
ttBackup -dir directory [-type backupType]
[-fname fileprefix] [-force]
{-connStr connection_string | DSN}
ttBackup has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be backed up. |
-dir directory |
Specifies the directory where the backup files should be stored. |
-fname fileprefix |
Specifies the file prefix for the backup files in the backup directory. The default value for this option is the file name portion of the DataStore parameter of the database's ODBC definition. |
-force |
Forces the backup into the specified directory. If a backup exists in that directory, ttBackup overwrites it. If this option is not specified, and you are creating a backup from a database other than the one previously backed up in the specified directory, ttBackup terminates with an end message without overwriting existing files. |
-h -help -? |
Prints a usage message and exits. |
-type backupType |
Specifies the type of backup to be performed. Valid values are:
|
-V | -version |
Prints the release number of ttBackup and exits. |
To perform a full file backup of the FastIns database to the backup directory in/users/pat/TimesTen/backups, use:
ttBackup -type fileFullEnable -dir /users/pat/TimesTen/backups FastIns
To copy the FastIns database to the file FastIns.back, use:
ttBackup -type streamFull FastIns > FastIns.back
On UNIX, to save the FastIns database to a backup tape, use:
ttBackup -type streamFull FastIns | dd bs=64k of=/dev/rmt0
To back up a database named origDSN to the directory /users/rob/tmp and restore it to the database named restoredDSN, use:
ttBackup -type fileFull -dir /users/rob/tmp -fname restored origDSN ttRestore -dir /users/rob/tmp -fname restored restoredDSN
The ttBackup utility and the ttRestore utility backup and restore databases only when the first three numbers of the TimesTen release and the platform are the same. For example, you can backup and restore files between TimesTen releases 11.2.2.2.0 and 11.2.2.6.0. You cannot backup and restore files between releases 11.2.1.9.0 and 11.2.2.6.0. You can use the ttBulkcp or CS (UNIX only) utility to migrate databases across major releases or operating systems. You can use ttMigrate together with ttMigrateCS (client server version of ttMigrate) to migrate databases between 32- and 64-bit platforms or bit levels. You must use the -relaxedUpgrade option when restoring data on a new bit-level. In the case of changing bit-levels, the database cannot be involved in a replication scheme. Follow the examples in "Moving a database between 32-bit and 64-bit platforms" in the Oracle TimesTen In-Memory Database Installation Guide.
When an incremental backup has been enabled, TimesTen creates a backup hold in the transaction log file. Call the ttLogHolds built-in procedure to see information about this hold. The backup hold determines which log records should be backed up upon subsequent incremental backups. Only changes since the last incremental backup are updated. A side effect to creating the backup hold is that it prevents transaction log files from being purged upon a checkpoint operation until the hold is advanced by performing another incremental backup or removed by disabling incremental backups.
Transactions that commit after the start of the backup operation are not reflected in the backup.
Up to one checkpoint and one backup may be active at the same time, with these limitations:
A backup never needs to wait for a checkpoint to complete.
A backup may need to wait for another backup to complete.
A checkpoint may need to wait for a backup to complete.
Databases containing cache groups can be backed up as normal with the ttBackup utility. However, when restoring such a backup, special consideration is required as the restored data within the cache groups may be out of date or out of sync with the data in the back end Oracle database. See the section on "Backing up and restoring a database with cache groups" in the Oracle TimesTen Application-Tier Database Cache User's Guide for details.
You cannot back up temporary databases.
Copies data between TimesTen tables and ASCII files. ttBulkCp has two modes:
In copy-in mode (ttBulkCp -i), rows are copied into an existing TimesTen table from one or more ASCII files (or stdin).
In copy-out mode (ttBulkCp -o), an entire TimesTen table is copied to a single ASCII output file (or stdout).
On UNIX, this utility is supported for TimesTen Data Manager DSNs. For Client DSNs, use the utility ttBulkCpCS.This utility only copies out the objects owned by the user executing the utility, and those objects for which the owner has SELECT privileges. If the owner executing the utility has the ADMIN privilege, ttBulkCp copies out all objects.
This utility requires the INSERT privilege on the tables it copies information into. It requires the SELECT privilege on the tables it copies information from.
If authentication information is not supplied in the connection string or DSN, this utility prompts for a user ID and password before continuing.
ttBulkCp {-h | -help | -? | -helpfull}
ttBulkCp {-V | -version}
ttBulkCp -i [-cp numTrans | final] [-d errLevel]
[-e errorFile] [-m maxErrs] [-sc] [-t errLevel]
[-u errLevel] [-v 0|1] [-xp numRows | rollback]
[-Cc | -Cnone] [-tformat timeFormat] [-tsformat timeStampFormat]
[-dformat | -D dateFormat] [-F firstRow] [-L lastRow]
[-N ncharEncoding] [-Q 0|1] [-S errLevel] [-dateMode dateMode]
[-[no]tblLock]{-connStr connection_string | DSN}
[owner.]tableName [dataFile ...]
ttBulkCp -o [-sc] [-v 0|1] [-A 0|1] [-Cc | -Cnone]
[-nullFormat formatStr}
[-tformat timeFormat] [-tsformat timeStampFormat]
[-dateMode dateMode] [-dformat | -D dateFormat]
[-N ncharEncoding] [-noForceSerializable | -forceSerializable]
[-tsprec precision] [-Q 0|1]
{-connStr connection_string | DSN} [owner.]tblName
[dataFile]
ttBulkCp has the options:
| Option | Description |
|---|---|
-Cnone
|
-Cnone disables the use of comments in the output file.-Cc sets the default comment character to c. If no default comment character is specified, the pound character (#) is used. The -C option takes the values: \t (tab) or any of the characters:~ ! @ # % ^ & * ( ) = : ; | < > ? , / This option overrides the COMMENTCHAR file attribute. |
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be copied. |
-D | -dformat
|
Sets the date format. For a list of legal fixed values, see "Date, time and timestamp values". This option overrides the DFORMAT file attribute. The default is ODBC.
See also: |
dataFile |
For copy-in mode, specifies the path name(s) of one or more ASCII files containing rows to be inserted into the table. If no files are given, the standard input is used. A single hyphen (-) is understood to mean the standard input. For copy-out mode, specifies the path name of the file into which rows should be copied. If no file is given, the standard output is used. A single hyphen (-) is understood to mean the standard output. |
-dateMode dateMode |
Specifies whether ttBulkCp treats an Oracle database DATE type as a simple date (without hour, minute and second fields) or as a timestamp (with hour, minute and second fields).
For copy-in mode, the default behavior for input is date. For copy-out mode, the default behavior for output is timestamp. TimesTen truncates the data and issues a warning if you select This option overrides the |
-h -help
|
Prints a short usage message and exits. |
-helpfull |
Prints a longer usage message and exits. |
-i |
Selects copy-in mode. |
-N ncharEncoding |
Specifies the input and output character encoding for NCHAR types. Valid values are UTF8, UTF-8 or ASCII. |
-o |
Selects copy-out mode. |
owner |
Specifies the owner of the table to be saved or loaded. If owner is omitted, TimesTen looks for the table under the user's name and then under the user name SYS. This parameter is case-insensitive. |
-Q [0 | 1] |
Indicates whether character-string values should be enclosed in double quotes.
|
-s c |
Sets the default field-separator character to c. If no default field-separator is specified, a comma (,) is used. The -s option takes the values \t (tab) or any of the characters:~ ! @ # % ^ & * ( ) = : ; | < > ? , / This option overrides the FSEP file attribute. |
tableName |
Specifies the name of the table to be saved or loaded. This parameter is case-insensitive. |
-tformat
|
Sets the time format. For a list of legal fixed values, see "Date, time and timestamp values". The default value is ODBC. This option overrides the TSFORMAT file attribute.
See also: |
-tsformat
|
Sets the timestamp format. For a list of legal fixed values, see "Date, time and timestamp values". The default value is DF*TF+FF, which is the concatenation of the date format, the time format and fractional seconds. This option overrides the TFORMAT file attribute.
See also: |
-V | -version |
Prints the release number of ttBulkCp and exits. |
-v [0 | 1] |
Sets the verbosity level.
|
Use the following options in copy-out (-o) mode only. You must have SELECT privileges on the specified tables.
| Option | Description |
|---|---|
-A [0 | 1] |
Indicates whether ttBulkCp should suppress attribute lines in the output file.
|
-forceSerializable -noForceSerializable |
The -forceSerializable option indicates that ttBulkCp should use serializable isolation regardless of the DSN or connection string settings. This is the default behavior.
If you specify the Warning: This output was produced using a non-serializable isolation level. It may therefore not reflect a transaction-consistent state of the table. For more information on isolation modes, see "Transaction isolation levels" in Oracle TimesTen In-Memory Database Operations Guide. |
-nullFormat formatStr |
Specifies the format in which NULL values are printed. Valid values are:
An empty LOB is printed as |
-tsprec precision |
When used with the -o option, truncates timestamp values to precision. ttBulkCp allows up to 6 digits in the fraction of a second field. Truncation may be necessary when copying timestamps using other RDBMS. |
Use the following options in copy-in (-i) mode only. You must have INSERT privileges on the specified tables.
| Option | Description |
|---|---|
-cp numTrans
|
Sets the checkpoint policy for the copy in.
A value of 0 indicates that A nonzero value indicates that A value of Periodic checkpoints can only be enabled if periodic commits are also enabled. See the |
-d error
|
By default, ttBulkCp does not consider rows that are rejected because of constraint violations in a unique column or index to be errors.
Regardless of the setting of |
-e errFile |
Indicates the name of the file in which ttBulkCp should place information about rows that cannot be copied into the TimesTen table because of errors. These errors include parsing errors, type-conversion errors and constraint violations. The value of errFile defaults to stderr. The format of the error file is the same as the format of the input file (see "Data file format"), so it should be possible to correct the errors in the error file and use the corrected error file as an input file for a subsequent run of ttBulkCp. |
-F firstRow |
Indicates the number of the first row that should be copied. Use this option (optionally with -L) to copy a subset of rows into the TimesTen table. Rows are numbered starting at 1. If more than one input file is specified, rows are numbered consecutively throughout all the files. The default value is 1. |
-L lastRow |
Indicates the number of the last row that should be copied. See the description of -F. A value of 0 specifies the last row of the last input file. The default value is 0. |
-m maxErrors |
Specifies the maximum number of errors to report.
The default is If set to |
-S error
|
By default, ttBulkCp issues an error when it encounters a value that exceeds its maximum scale. This error can be generated for a decimal value whose scale exceeds the maximum scale of its column or for a TIMESTAMP value with more than 6 decimal places of fractional seconds (sub-microsecond granularity).
|
-t error
|
By default, ttBulkCp issues an error when a CHAR, VARCHAR2, NCHAR, NVARCHAR2, BINARY, VARBINARY, BLOB, CLOB, or NLOB value is longer than its maximum column width.
|
-[no]tblLock |
Specifies whether to use table-level or row-level locking, when copying rows into a TimesTen table.
For a single input stream into a table, using |
-u error
|
By default, ttBulkCp issues an error when a real, float or double attribute underflows. Underflow occurs when a floating point number is so small that it is rounded to zero.
|
-xp numRows
|
Sets the transaction policy for the load. A value of 0 indicates that ttBulkCp should perform the entire load as a single transaction and should commit that transaction whether the load succeeds or fails.
A value of A nonzero value indicates that The default value is Use the |
This section describes the format the dataFile parameter.
Each line of a ttBulkCp input file is either a blank line, a comment line, an attribute line or a data line.
Blank lines are lines with no characters at all, including whitespace characters (space and tab). Blank lines are ignored by ttBulkCp.
Comment lines begin with the comment character. The default comment character is #; this default can be overridden with the -C command-line option or the COMMENTCHAR file attribute (see "File attribute line format"). The comment character must be the first character on the line. Comment lines are ignored by ttBulkCp. Comments at the end of data lines are not supported.
File attribute lines are used for setting file attributes that control the formatting of the data file. Attribute lines begin with the ten-character sequence ##ttBulkCp. The section "File attribute line format" describes the full syntax for attribute lines. Attribute lines can appear anywhere in the data file.
Data lines contain the rows of the table being copied. Data lines in the data file and rows of the table correspond one-to-one; that is, each data line completely describes exactly one row. Each data line consists of a list of column values separated by the field separator character. The default field separator is a comma (,). This default can be overridden by the -s command-line option or the FSEP file attribute. The section "Data line format" describes the full syntax for data lines.
The format of an attribute line is:
##ttBulkCp[:attribute=value]...
Attribute lines always begin with the ten-character sequence ##ttBulkCp, even if the comment character is not #. This sequence is followed by zero or more file attribute settings, each preceded by a colon.
File attribute settings remain in effect until the end of the input file or until they are changed by another attribute line in the same input file. The values of any file attributes that are omitted in an attribute line are left unchanged.
Most command line options take precedence over the values in the file attributes that are supported by ttBulkCp. The CHARACTERSET attribute is the only file attribute that overrides command line options.
The file attributes are:
CHARACTERSET: Specifies the character set to be used to interpret the data file. If the file attribute is not set, the character set used to interpret the file is the one specified in the ConnectionCharacterSet connection attribute. For best performance, the value of the DatabaseCharacterSet connection attribute should match either the ConnectionCharacterSet connection attribute or this file attribute. If the character set supplied in ConnectionCharacterSet connection attribute or in this file attribute is different than the actual character set of the file, ttBulkCp may interpret data incorrectly.
VERSION: Specifies the version of the file format used in the file, expressed as major.minor. The only supported version is 1.0.
DATEMODE: Specifies whether an Oracle database DATE type is specified as simple date or as timestamp.
FSEP: Specifies the field separator character used in the file. The field separator can be set to \t (tab) or any of the characters: ~ ! @ # $ % ^ & * ( ) = : ; | < > ? , / .
QUOTES: Indicates whether character string values in the file are enclosed in double quotes. The value can be 0, to indicate that strings are not quoted, or 1, to indicate that strings are quoted. This value can be overridden with the -Q option.
COMMENTCHAR: Specifies the comment character used in the file. The comment character can be set to \t (tab) or any of the characters: ~ ! @ # $ % ^ & * ( ) = : ; | < > ? , / .
The comment character can also be set to the value none, which disables the use of comments in the data file.
DFORMAT: Sets the date format. For a list of legal values, see "Date, time and timestamp values". When a custom format is used, it should be enclosed in single quotes. This value can be overridden with the -D/-dformat command-line option. See also: TFORMAT and TSFORMAT.
NCHARENCODING: Indicates the encoding to be used for the NCHAR and NVARCHAR2 data types. The value may be either ASCII or UTF-8.
TFORMAT: Indicates the time format. For a list of legal values, see "Date, time and timestamp values". When a custom format is used, it should be enclosed in single quotes. This value can be overridden with the -tformat command-line option. See also: DFORMAT and TSFORMAT.
TSFORMAT: Sets the timestamp format. For a list of legal values, see "Date, time and timestamp values". When a custom format is used, it should be enclosed in single quotes. This value can be overridden with the -tsformat command-line option. See also: DFORMAT and TFORMAT.
The following header line sets the field separator character to $ and disables quoting of character strings:
##ttBulkCp:FSEP=$:QUOTES=0
The following header line disables comments and sets the date format to the Oracle format:
##ttBulkCp:COMMENTCHAR=none:DFORMAT=Oracle
The following header line set the date format to a custom format:
##ttBulkCp:DFORMAT='Mon DD, YYYY'
Data lines contain the row data of the table being copied. Each data line corresponds to a row of the table; rows cannot span input-file lines. A data line consists of a list of column values separated by the field separator character. Unnecessary whitespace characters should not be placed either before or after the field separator. The format of each value is determined by its type.
NULL values can either be expressed as NULL (all capitals, no quotes) or as empty fields.
CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB, NCLOB: If quoting of character strings is enabled (the default), then strings and characters must be enclosed in double quotes. If quoting of character strings is disabled, then any double-quote characters in the string are considered to be part of the string itself. ttBulkCp recognizes the following backslash escapes inside a character string, regardless of whether quoting of strings is enabled:
\" The double-quote character. If character-string quoting is enabled, then all double quote characters in the string must be escaped with a backslash. If character-string quoting is disabled, then it is permissible, but not necessary, to use the backslash.
\t The tab character.
\n The newline character.
\r The carriage return character.
\\ The backslash character.
\xyz (CHAR and VARCHAR2 only) The character whose ASCII value is xyz, where xyz is a three-character octal number, as in \033.
\uxyzw (NCHAR and NVARCHAR2 only) The character whose unicode value is xyzw, where xyzw is a four-digit hexadecimal number, as in\ufe4a. The \uxyzw notation is supported in both UTF-8 and ASCII encoding modes.
In addition, any of the ~ ! @ # $ % ^ & * ( ) = : ; | < > ? , / characters can be escaped with a backslash. Although it is unnecessary to escape these characters usually, doing so prevents them from being mistaken for a comment character or a field separator when character-string quoting is disabled.
If character-string quoting is enabled, the empty string (represented as " ") is distinct from NULL. If character-string quoting is disabled, then empty strings cannot be represented, as they cannot be distinguished from NULL.
For unicode strings, unicode characters encoded using UTF-8 multibyte sequences are supported in the UTF-8 encoding mode only. If these sequences are used with the ASCII encoding mode, ttBulkCp interprets each byte in the sequence as a separate character.
For fixed-length CHAR and NCHAR fields, strings that are shorter than the field length are padded with blanks. For VARCHAR2 and NVARCHAR2 fields, the string is entered into TimesTen exactly as given in the data file. Trailing blanks are neither added nor removed.
BINARY, VARBINARY, BLOB: If quoting of character strings is enabled (the default), binary values are delimited by curly braces ({...}). If quoting of character strings is disabled, then curly braces should not be used. Whether character-string quoting is enabled or disabled, binary values may start with an optional 0x or 0X.
Each byte of binary data is expressed as two hexadecimal digits. For example, the four-byte binary string:
01101000 11001010 01001001 11101111
would be expressed as the eight-character hexadecimal string:
68CA49EF
Digits represented by the letters A through F can either be upper- or lower-case. The hexadecimal string cannot contain white spaces. Because each pair of characters in the hexadecimal string is converted to a single binary byte, the hexadecimal string must contain an even number of characters. For fixed-length binary fields, if the given value is shorter than the column length, the value is padded with zeros on the right. For VARBINARY values, the binary value is inserted into TimesTen exactly as given in the data file.
If character-string quoting is enabled, a zero-length binary value (represented as { }) is distinct from NULL. If character-string quoting is disabled, then zero-length binary values cannot be represented, as they cannot be distinguished from NULL.
TINYINT, SMALLINT, INTEGER, BIGINT: Integer values consist of an optional sign followed by one or more digits. Integer values may not use E-notation. Examples:
-14 98765 +186
REAL, FLOAT, DOUBLE: Floating-point values can be expressed with or without decimal points and may use E-notation. Examples:
3.1415 -0.00004 1.1e-3 5e3 .56 -682 -.62E-4 170.
DECIMAL, NUMERIC: Decimal values can be expressed with or without decimal points. Decimal values may not use E-notation. Examples:
5 -19.5 -11 000 -.1234 45. -57.0 0.8888
Inf, -Inf and Nan values: Infinity and Not a Number values can be represented as strings to represent the corresponding constant value (all are case insensitive):
| String | Value |
|---|---|
NAN |
NaN |
[+]INF |
Inf |
-INF |
-Inf |
TimesTen outputs the values as: NAN, INF and -Inf.
Date, time and timestamp values
Formats for date, time and timestamp values can be specified either by selecting a fixed datetime format or by defining a custom datetime format. The custom datetime formats are defined using format specifiers similar to those used by the TO_DATE and TO_CHAR SQL functions, as described in the following table.
In many cases, it is not necessary to define the timestamp format, even when a custom date or time format is used, because the default TimesTen format (DF*TF+FF) is defined in terms of the date and time formats. Therefore, setting the date format sets not only the format for date values, but also for the date portion of timestamp values. Similarly, setting the timestamp format affects both time values and the time portion of the timestamp values.
| Specifier | Descriptions and restrictions |
|---|---|
Q |
Quarter. Cannot be used in copy-in mode. |
YYYY |
Year (four digits). |
Y,YYY |
Year (with comma as shown). |
YYY |
Year (last three digits). Cannot be used in copy-in mode. |
Y |
Year (last digit). Cannot be used in copy-in mode. |
MONTH |
Month (full name, blank-padded to 9 characters, case-insensitive). |
MON |
Month (three character prefix, case-insensitive). |
MM |
Month (01 through 12). |
DD |
Day of the month (01 through 31). |
HH24 |
Hour (00 through 23). |
HH12 |
Hour (01 through 12). Must be used with AM/PM for copy-in mode. |
HH |
Hour (01 through 12). Must be used with AM/PM for copy-in mode. |
MI |
Minute (00 through 59). |
SS |
Second (00 through 59). |
FF |
Fractional seconds.Six digits, unless overridden with the -tsprec option. |
FFn |
Fractional seconds (number of digits specified by n). |
+FF |
In copy-in mode, matches, optional decimal point plus one or more fractional seconds. In copy-out mode, same as .FF. |
+FFn |
In copy-in mode, same as +FF. In copy-out mode, same as .FFn. |
AM PM |
Meridian indicator without dots. In copy-in mode, this must be used with HH or HH12, but not HH24. |
| A.M.
P.M. |
Meridian indicator with dots. In copy-in mode, this must be used with HH or HH12, but not HH24. |
DF |
Current date format (can only be used in timestamp format). |
TF |
Current time format (can only be used in timestamp format). |
- / ; : |
Punctuation that are matched in copy-in mode or output in copy-out mode. |
"text" |
Text that is matched in input mode or output in copy-out mode. |
* |
Matches 0 or more whitespace characters (space or tab) in copy-in mode or outputs 1 space in copy-out mode. |
Fixed date, time and timestamp formats
For date values, the fixed formats are:
| Format | Description |
|---|---|
| ODBC | YYYY-MM-DD
Example: (default value) |
| Oracle | DD-Mon-YYYY
Example: |
| SYBASE1 | MM/DD/YYYY
Example: |
| SYBASE2 | DD-MM-YYYY
Example: |
| SYBASE3 | Mon*DD*YYYY
Example: |
For time values, the only fixed format is ODBC:
| Format | Description |
|---|---|
| ODBC | HH24:MI:SS
Example: |
For timestamp values, the fixed formats are:
| Format | Description |
|---|---|
| ODBC | YYYY-MM-DD*HH24:MI:SS+FF
Example: |
| Oracle | DD-Mon-YYYY*HH24:MI:SS+FF
Example: |
| SYBASE1 | MM/DD/YYYY*HH24:MI:SS+FF
Example: |
| SYBASE2 | DD-MM-YYYY*HH24:MI:SS+FF
Example: |
| SYBASE3 | Mon*DD*YYYY*HH24:MI:SS+FF
Example: J |
The default timestamp value is: 'DF*TF+FF'
The following input file is for a table with five columns: two char columns, a double column, an integer column and a VARBINARY column. In the "Mountain View" line, the last three columns have NULL values.
##ttBulkCp
# This is a comment.
###### So is this.
# The following line is a blank line.
"New York","New York",-345.09,12,{12EF87A4E5}
"Milan","Italy",0,0,{0x458F}
"Paris","France",1.4E12,NULL,{F009}
"Tokyo","Japan",-4.5E-18,26,{0x00}
"Mountain View","California",,,
Here is an equivalent input file in which quotes are disabled, the comment character is '$' and the field separator is '|':
##ttBulkCp:QUOTES=0:COMMENTCHAR=$:FSEP=| $ This is a comment. $$$$$$ So is this. $ The following line is a blank line. New York|New York|-345.09|12|12EF87A4E5 Milan|Italy|0|0|0x458F Paris|France|1.4E12|NULL|F009 Tokyo|Japan|-4.5E-18|26|0x00 Mountain View|California|||
The following command dumps the contents of table mytbl from database mystore into a file called mytbl.dump.
ttBulkCp -o mystore mytbl mytbl.dump
The following command loads the rows listed in file mytbl.dump into a table called mytbl on database mystore, placing any error messages into the file mytbl.err.
ttBulkCp -i -e mytbl.err mystore mytbl mytbl.dump
The above command terminates after the first error occurs. To force the copy to continue until the end of the input file (or a fatal error), use -m 0, as in:
ttBulkCp -i -e mytbl.err -m 0 mystore mytbl mytbl.dump
To ignore errors caused by constraint violations, use -d ignore, as follows.
ttBulkCp -i -e mytbl.err -d ignore mystore mytbl mytbl.dump
ttBulkCp explicitly sets the Overwrite connection attribute to 0, to prevent accidental destruction of a database. For more information, see "Overwrite".
Real, float or double values may be rounded to zero when the floating point number is small.
The connection attribute PassThrough with a nonzero value is not supported with this utility and returns an error.
When specifying date, time and timestamp formats, incomplete or redundant formats are not allowed in input mode. Specifiers that reference fields that are not present in the data type (for example a minute specifier in a date format) return errors in copy-out mode. In copy-in mode, the values of those specifiers are ignored.
The following caveats apply when disabling quoted strings in the ttBulkCp data file:
Empty strings and zero-length binary values cannot be expressed, as they cannot be distinguished from NULL.
If the field separator character appears inside a character string, it must be escaped with a backslash or else it is treated as an actual field separator.
If a data line begins with a character string and that string begins with the comment character, that character must be escaped with a backslash or else the line is treated as a comment. If there are no actual comments in the file, set the comment character to none to avoid characters from being misread as comment characters.
For UTF-8, NCHAR are converted to UTF-8 encoding and then output. UTF-8 input is converted to NCHAR.
For ASCII, those NCHAR values that correspond to ASCII characters are output as ASCII. For those NCHAR values outside of the ASCII range, the escaped Unicode format is used.
On Windows, this utility is supported for all TimesTen Data Manager and Client DSNs.
It is recommended that you do not run DDL SQL commands while running ttBulkCp to avoid lock contention issues for your application.
Assists in configuring a TimesTen Cache for optimal performance and minimal storage overhead. This utility evaluates a captured SQL workload running on a target Oracle database, or an existing SQL tuning set. It also evaluates the schema definitions from the target database.
This utility analyzes the table and column usage patterns, and recommends TimesTen cache group definitions to improve the workload performance by generating a report and an implementation script. It also optionally evaluates the performance of the recommended cache and compares it with the performance of the target Oracle database.
General analysis
ttCacheAdvisor
-oraTarget
{-oraConn Oracle_connection_string} ...
-oraDirObject Oracle_directory_object
[{-oraDirNfs path} | {-ftp network_connection_string}]
-oraRepository
-oraConn Oracle_connection_string
-oraDirObject Oracle_directory_object
[{-oraDirNfs path} | {-ftp network_connection_string}]
-ttConn TimesTen_connection_string
[-captureCursorCache minutes] [-flushSharedPool] [-plsqlInfo]
[-cacheSize {{size{MB|GB|TB}} | UNLIMITED}]
[-writethruThreshold percent%]
[-report path]
[-evalSqlPerf [maximum[%]]]
[-task task_name]
[-description string]
[-rerun]
[-showSql]
[-trace [traceName]]
[{-import [-noSchema] path} ...]
[-add
{-tableAttrib [owner.]table_name
{-pk '(column_name, ...)' |
-fk '(column_name, ...) REFERENCES (primary_key_column_name, ...)
[ON DELETE CASCADE]' |
-where '(predicate)'} ...
} ...]
[-drop
{-tableAttrib [owner.]table_name
{-pk | -fk | -where} ...
} ...]
[{{-add | -drop} -sqlSet [owner.]sql_set_name}]
[{-command | @} path]
You can repeat the options for -oraTarget to specify multiple users for the same target Oracle database to analyze objects from more than one schema. There can be only one Oracle repository specification in a Cache Advisor evaluation run.
String values may be optionally enclosed in single or double quotes. If the string begins with a dash (-), then the string must be enclosed in single or double quotes.
Print a usage message and exit.
ttCacheAdvisor {{-help | -h} [option]}
Print the release number of ttCacheAdvisor and exit.
ttCacheAdvisor {-V | -version}
Export a workload and schema definitions from the target Oracle database to files:
ttCacheAdvisor
[{-command|@} path]
{-oraTarget
-oraConn oracle_connection_string
-oraDirObject oracle_directory_object
[{-oraDirNfs| -ftp} network_connection_string]
} ...
-captureCursorCache minutes [-flushSharedPool]
-export [-zip] path
[-showSql]
Display a summary or details of existing tasks in the repository Oracle database:
ttCacheAdvisor [{-command|@} path] -oraRepository -oraConn oracle_connection_string
-showTask [task_name]
[-showSql]
Drop an existing task from the repository Oracle database:
ttCacheAdvisor [{-command|@} path] -oraRepository -oraConn oracle_connection_string
-dropTask task_name
[-showSql]
For more information about using Cache Advisor to capture and analyze a SQL workload running on a target Oracle database, see Oracle TimesTen Application-Tier Database Cache User's Guide.
ttCacheAdvisor has the options:
| Option | Description |
|---|---|
{-add | -drop} |
-add adds the specified item to the ttCacheAdvisor task.
Use these options to add or drop cache group and cache table attributes, and workload options. |
-cacheSize {{size{MB|GB|TB}} | UNLIMITED} |
Specifies the maximum TimesTen database size in megabytes (MB), gigabytes (GB) or terabytes (TB). The default is UNLIMITED.
The value should be set to amount of the permanent memory available on the system where you plan to deploy TimesTen Cache. |
-captureCursorCache minutes |
Specifies that ttCacheAdvisor capture a SQL workload from the Oracle cursor cache on the Oracle target database. The capture operation occurs as a series of snapshots and lasts for the specified number of minutes. Fractions of minutes can be specified using a decimal point value for minutes.
The Oracle target database manages its cursor cache by unloading cursors for specific SQL statements based upon internal heuristics. Therefore, it is not possible to predict exactly which cursors for which SQL statements will be in the Oracle cursor cache when a given cursor cache snapshot is captured. Oracle recommends a capture duration of at least 10 minutes to avoid having some SQL statements not being captured. However, certain application workload behaviors or a small Oracle cursor cache may require a longer capture duration to avoid SQL statements not being captured. |
{-command|@} path |
Specifies a file of ttCacheAdvisor commands. You can use this option anywhere on the command line that an option is allowed. Command files can be nested to any depth if they are not recursive. Blank lines and lines that start with the # comment delimiter are ignored in the files. |
-description string |
Specifies a description of the ttCacheAdvisor task. The description can be up to 4000 bytes in length. |
-dropTask task_name |
Drops the specified task, including SQL tuning sets created or copied on behalf of the task that are not being used by any other tasks. |
-evalSqlPerf [max[%]] |
Specifies that ttCacheAdvisor compare the performance of the SQL workload statements in the TimesTen database with the target Oracle database. The -evalSqlPerf option should only be used on a test target database and not on a production target database.
You can specify a number or a percentage of SQL statements to evaluate. Include the If you limit the number of SQL statements to evaluate, then When using the |
-export [-zip] path |
Specifies that ttCacheAdvisor export the workload captured with the -captureCursorCache option.
The -export option cannot be used with the The If the |
-fk '(column_name, ...) REFERENCES (primary_key_column_name, ...) [ON DELETE CASCADE]' |
Specifies a foreign key for the table. If the specified foreign key creates a cycle with an existing foreign key in the Oracle database, then ttCacheAdvisor uses the specified foreign key and not the existing foreign key.
'( |
-flushSharedPool |
Flushes the shared pool on the target Oracle database before capturing a workload. Can only be specified with the -captureCursorCache option.
Use the |
{-help | -h} [option] |
Prints a usage message and exits. |
-import [-noSchema] path |
Specifies that ttCacheAdvisor import workloads and schemas that have previously been exported.
The -import option cannot be used with the Use
The If you exported the workloads and schema using the |
-oraConn Oracle_connection_string |
Specifies the Oracle database user and optional password, Oracle Net Service Name, and any optional connection attributes. The standard format of an Oracle connection string is:
If asterisk ( No more than one connection to the repository Oracle database can be specified. Multiple connections can be specified to the Oracle target database to analyze the schema definitions from multiple target schemas and to facilitate performance evaluation of SQL statements that were originally executed by different Oracle target database users. To specify multiple connections to the Oracle target database, specify the
|
-oraRepository |
Specifies the repository Oracle database (version 11.2.0.2 or later) used by ttCacheAdvisor to perform analysis of application workload and schema definitions.
If either |
-oraTarget |
Specifies the target Oracle database (version 10.2.0.4 or later) to cache in a TimesTen database.
If either |
-pk '(column_name, ...)' |
Specifies a primary key for the table. This overrides any primary key on the Oracle database table.
'( |
-plsqlInfo |
Augments the captured workload with information about the PL/SQL objects from which SQL statements originated. Can only be specified with the -captureCursorCache option.
The workload augmentation process may increase the load on the target database. |
-report path |
Specifies a directory on the TimesTen system where the ttCacheAdvisor writes the recommendation report and implementation script. The default is the task_name directory where ttCacheAdvisor was invoked.
The specified directory cannot exist as the |
-rerun |
Specifies that ttCacheAdvisor rerun the current task. The -rerun option must be used with the -task task_name option. |
-showSql |
Specifies that ttCacheAdvisor display the SQL statements it executes on the TimesTen database, the target Oracle database and the repository Oracle database. ttCacheAdvisor prompts for continuation after displaying the statements.
Use this option to assess the impact of |
-showTask [task_name] |
Displays information about the specified task or all tasks. If task_name is not specified, then summary information is displayed about all tasks stored in the repository Oracle database. If task_name is specified, then detailed information is displayed about the specified task. |
-sqlSet [owner.]sql_set_name |
Specifies a SQL tuning set to add or drop from the ttCacheAdvisor task. When -add is specified, ttCacheAdvisor looks for the specified SQL tuning set first on the repository Oracle database and then on the target Oracle database. When -drop is specified, ttCacheAdvisor drops the SQL tuning set from the task. If the SQL tuning set was created or copied on behalf of the task, then ttCacheAdvisor also permanently drops the SQL tuning set from the repository database.
You can add or drop multiple SQL sets on the command line. For example: -add -sqlSet ADVISOR.TEST1 -add -sqlSet ADVISOR.TEST2 |
-tableAttrib [owner.]table_name |
Specifies the cache group attributes and cache table attributes for ttCacheAdvisor to use for caching recommendations. The schema and table name can include a % wildcard character. When dropping an attribute, the schema and table name must match what was specified when they were added, including any wildcard characters.
Using a wildcard character for the schema or table name, you can specify an attribute to apply to more than one table. |
-task task_name |
Specifies a task name. The name can be up to 30 bytes in length and must be unique among ttCacheAdvisor tasks stored in the repository Oracle database. In other words, no task with the name task_name can exist at the time you run the ttCacheAdvisor utility. Otherwise, the task must first be dropped using the -dropTask option.
A task is an object that contains information about the workload, performance results and Use the task name to run, rerun, show or drop the task. The default task name is |
-trace [traceName] |
Captures debug trace information that can be provided to Oracle TimesTen Customer Support.
By default, all trace files are placed in the directory:
If you provide a trace name with the
If the zip executable exists in any of the directories set in the |
-ttConn TimesTen_connection_string |
Specifies a TimesTen database for ttCacheAdvisor to use for cache validation and evaluation.
Example:
|
-V | -version |
Prints the release number of ttCacheAdvisor and exits. |
-where '(predicate)' |
Specifies a WHERE clause for the table if using a readonly cache group. TimesTen ignores the value of this option for an AWT cache group.
The format of
|
-writethruThreshold percent% |
Specifies a threshold of update or write operations, expressed as a percentage, including the % character as a suffix. If the percentage of update operations in the workload on a table or related set of tables is less than or equal to the specified threshold, then ttCacheAdvisor recommends a read-only cache group to cache the Oracle database tables. Otherwise, ttCacheAdvisor recommends an asynchronous writethrough (AWT) cache group.
The default threshold is zero which means that |
The following options are recommended for advanced Cache Advisor users. You can use these options for improved file transfer performance with the -export and -import options:
| Option | Description |
|---|---|
-ftp network_connection_string |
Specifies a network connection for transferring files between the target Oracle database, repository Oracle system and TimesTen database.
By default, Cache Advisor uses the OCI connection specified with the You must precede the |
-oraDirNfs path |
Specifies a network connection for transferring files between the target Oracle database system, repository Oracle database system, and TimesTen database system.
You must precede the By default, Cache Advisor uses the OCI connection specified with the |
-oraDirObject Oracle_directory_object |
Specifies an Oracle database directory object that ttCacheAdvisor uses to export and import workload and schema information to and from dump files using Data Pump. The directory object must reference a directory path in a local file system on the target Oracle database host when used with the -oraTarget option, or a directory path in a local file system on the repository Oracle database host when used with the -oraRepository option.The default directory object is TTCA_DIRECTORY, which is created during Cache Advisor setup. The TTCA_DIRECTORY directory object is not configured for use with the -oraDirNfs or -ftp options. Use the -oraDirObject option when you use either the -oraDirNfs or -ftp options.
You must precede the |
Capture a SQL workaround on the target database for a duration of 30 minutes. Flush the shared pool on the target database before capturing the workload. Analyze the workload and produce a report in the ./testtask directory.
% ttCacheAdvisor -oraTarget -oraConn orauser@targetdb \ -oraRepository -oraConn advisor@repositorydb \ -ttConn "DSN=cacheadvisor;UID=cacheuser" \ -captureCursorCache 30 -flushSharedPool -task testtask
Capture a SQL workaround on the target database for a duration of 15 minutes. Evaluate the performance of all SQL statements executed in the TimesTen database and in the target database. Write the HTML report files to the /home/ttuser/cacheadvreport directory.
% ttCacheAdvisor -oraTarget -oraConn orauser@targetdb \ -oraRepository -oraConn advisor@repositorydb \ -ttConn "DSN=cacheadvisor;UID=cacheuser" \ -report /home/ttuser/cacheadvreport -captureCursorCache 15 -evalSqlPerf
Capture a SQL workaround on the target database for a duration of 10 minutes. Flush the shared pool on the target database before capturing the workload. Export the captured workload into a single file named cacheadvcapture.zip written to the /home/ttuser directory.
% ttCacheAdvisor -oraTarget -oraConn orauser@targetdb \ -captureCursorCache 10 -flushSharedPool -export -zip \ /home/ttuser/cacheadvcapture
Import and analyze the SQL workload from the /home/ttuser/cacheadvcapture.zip file. Write the HTML report files to the /home/ttuser/cacheadvreport directory.
% ttCacheAdvisor -oraTarget -oraConn orauser@targetdb \ -oraRepository -oraConn advisor@repositorydb \ -ttConn "DSN=cacheadvisor;UID=cacheuser" \ -report /home/ttuser/cacheadvreport -task temptask \ -import /home/ttuser/cacheadvcapture
Captures information about the state of TimesTen at the time the command is used. This information may be useful in diagnosing problems. Sometimes TimesTen Customer Support must make repeated incremental requests for information to diagnose a customer's problem in the field.
The information captured by this utility may be requested by TimesTen Customer Support and may be sent with your support email.
The utility does not interpret errors. It only collects information about the state of things and sends output to the ttcapture.date.number.log file in the directory from which you invoke the ttCapture utility. This utility collects general information that is usually relevant to support cases.
Note:
You should always enclose directory and file names in double quotes, in case there are spaces in them.This utility requires the instance administrator privilege.
If authentication information is not supplied in the connection string or DSN, this utility prompts for a user ID and password before continuing.
ttCapture {-h | -help | -?}
ttCapture {-V | -version}
ttCapture [-noinstinfo] [-nosysinfo] [-stdout | -dest dir] [-logdir dir]
[dspath | DSN]
ttCapture [-noinstinfo] [-nosysinfo] [-stdout | -dest dir] [-logdir dir]
[-noconnect] [dspath | DSN]
ttCapture -noconnect [dspath | DSN]
ttCapture has the options:
| Option | Description |
|---|---|
-dest dir |
Writes the output file to the designated directory. |
DSN |
Specifies an ODBC data source name of the database to be checked. |
dspath |
Specifies the fully qualified name of the database to be evaluated. This is not the DSN associated with the connection but the fully qualified database path name associated with the database as specified in the DataStore= parameter of the database's ODBC definition.
For example, for a database consisting of files NOTE: The |
-h
|
Prints a usage message and exits. |
-logdir dir |
Specifies the location of the log directory. Must be used with the -dspath option. If not specified, the log directory may not be available. |
-noconnect |
Specifies that the utility should capture information on the DSN without connecting to it.
If specified, some information, such as This option is useful if you do not want to load a large database or if you are reporting a problem where connections are failing. |
-noinstinfo |
Indicates that ttCapture should not capture any installation information. |
-nosysinfo |
Indicates that ttCapture should not capture any system information. |
-stdout |
On UNIX systems, ttCapture writes all output to stdout, instead of writing the output to a file. On Windows, ttCapture writes to a Command prompt. |
-V | -version |
Prints the release number of ttCapture and exits. |
To capture data on the test_db database and write the database checkpoint files to the directory D:\my_data\recover\test_db, use:
ttCapture -dest "D:\my_data\recover\test_db" test_db
Performs internal consistency checking within a TimesTen database. You can specify a specific structure to be checked and a desired level of checking.
This utility requires the ADMIN privilege.
If authentication information is not supplied in the connection string or DSN, this utility prompts for a user ID and password before continuing.
ttCheck {-h | -help | -?}
ttCheck {-V | -version}
ttCheck [ [-blkDir] [-compHeap] [-header] [-heap] [-indexHeap] [-log]
[-permBlkDir] [-permHeap] [-tempBlkDir] [-tmpHeap]
[-tables tblName [...]] [-users userName [...]]
[-level levelNum] ] [...]
[-m maxErrors] [-f outFile] [-v verbosity]
{DSN | [-connstr] connection_string | dspath}
ttCheck has the options:
| Option | Description |
|---|---|
-blkDir |
Checks all the block directories. |
-compHeap |
Checks the compilation heap structure. |
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be checked. |
dspath |
The fully qualified name of the database to be checked. This is not the DSN associated with the connection. It is the fully qualified database path name associated with the database as specified in the DataStore= parameter connection attribute in the database's DSN.
For example, for a database consisting of files |
-f outFile |
Specifies the output file name; defaults to stdout. |
-h
|
Prints a usage message and exits. |
-header |
Checks the content of the database header. |
-heap |
Checks all heap structures. |
-indexHeap |
Checks the index heap structure. |
-level levelNum |
Indicates the level of checking for header, block directory, heap and table. Different structures can be checked using different levels in a same command. A level specification is applied to all structures specified to its left in the command string that do not have a level specification. A level specification is applied to all structures if no structure is specified in the command string.
|
-log |
Checks the log buffer. |
-m maxErrors |
Maximum number of errors to report. Default is 10; a few extra related errors may be reported. If 0, the utility only connects, then returns. |
-permBlkDir |
Checks the permanent partition block directory. |
-permHeap |
Checks the permanent heap structure. |
-tables tblName [...] |
Checks table(s) specified by tblName. |
-tempBlkDir |
Checks the temporary partition block directory. |
-tmpHeap |
Checks the temporary heap structure. |
-users userName [...] |
Checks tables belonging to the user(s) specified by userName. |
-V | -version |
Prints the release number of ttCheck and exits. |
-v verbosity |
0 - No output (program's exit status indicates if an error was found).
|
To perform a check of all structures in the test_db database, use:
ttCheck test_db
To perform a sanity check of all structures in the test_db database, use:
ttCheck -level 1 test_db
To perform a check of all tables in the test_db database, use:
ttCheck -tables test_db
To check the physical structures and row contents of all tables in the test_db database, use:
ttCheck -tables -level 3 test_db
To perform a sanity check of all heap structures, row contents and indexes of all tables in the test_db database, use the following.
ttCheck -heap -level 1 -tables -level 4 test_db
To check the physical structures and row contents of tables tab1 and tab2 in the test_db database, use:
ttCheck -tables tab1 tab2 -level 3 test_db
While primarily intended for use by TimesTen customer support to diagnose problems with internal data structures of a TimesTen database, the information returned by ttCheck may be useful to system administrators and developers.
The ttCheck utility should be run when there are no active transactions on the system.
The ttCheck utility checks views in the same manner as other tables in a database. The utility cannot verify that the contents of a view matches view query's result.
If no structures are specified, ttCheck checks all structures. No errors are returned if a specified table's name or user is not found.
This utility may take some time to run. Verbosity level 2 enables you to print a progress report.
This utility is supported only where the TimesTen Data Manager is installed.
Manages TimesTen active standby pairs that take advantage of the high availability framework of Oracle Clusterware. This utility starts administrative processes, generates scripts and performs other functions to administer active standby pairs and the corresponding Clusterware resources.
For more information about using Oracle Clusterware to manage TimesTen active standby pairs, see Oracle TimesTen In-Memory Database Replication Guide.
These commands are available only with advanced high availability:
ttCWAdmin -addMasterHosts
ttCWAdmin -addSubscriberHosts
ttCWAdmin -createVIPs
ttCWAdmin -delMasterHosts
ttCWAdmin -delSubscriberHosts
ttCWAdmin -dropVIPs
These commands fail with basic high availability.
On Windows 2008, a user with Administrators privileges can execute all commands as Administrator. On other supported Windows platforms, any user that has Administrator privileges can execute all commands in this utility.
On UNIX, the root user can execute all commands in this utility. These commands must be executed by the root user:
ttCWAdmin -addMasterHosts
ttCWAdmin -addSubscriberHosts
ttCWAdmin -createVIPs
ttCWAdmin -delMasterHosts
ttCWAdmin -delSubscriberHosts
ttCWAdmin -ocrConfig
ttCWAdmin -dropVIPs
The administrator user can execute all other commands in this utility.
If authentication information is not supplied in the connection string or DSN, this utility prompts for a user ID and password before continuing.
ttCWAdmin {-h | -help | -?}
ttCWAdmin {-V | -version}
ttCWAdmin -init [-hosts "host_name1, host_name2[, ...]"]
ttCWAdmin {-createVIPs | -dropVIPs | -create | -drop | -restore | -start |
-stop | -status} [-ttclusterini path] [-dsn DSN]
ttCWAdmin -switch [-timeout seconds] -dsn DSN
ttCWAdmin -relocate -dsn DSN
ttCWAdmin -reauthenticate -dsn DSN
ttCWAdmin -ocrConfig
ttCWAdmin -beginAlterSchema -dsn DSN
ttCWAdmin -endAlterSchema -dsn DSN
ttCWAdmin -addMasterHosts [-hosts "host_name1, host_name2[, ...]"] -dsn DSN
ttCWAdmin -delMasterHosts [-hosts "host_name1, host_name2[, ...]"] -dsn DSN
ttCWAdmin -addSubscriberHosts [-hosts "host_name1, host_name2[, ...]"] -dsn DSN
ttCWAdmin -delSubscriberHosts [-hosts "host_name1, host_name2[, ...]"] -dsn DSN
ttCWAdmin -start [-noapp] -dsn DSN
ttCWAdmin -stop -dsn DSN
ttCWAdmin -startapps -dsn DSN
ttCWAdmin -stopapps -dsn DSN
ttCWAdmin -shutdown [-hosts "host_name1, host_name2[, ...]"]
ttCWAdmin has these options:
| Option | Description |
|---|---|
-addMasterHosts |
Adds spare hosts to the pool of master hosts dynamically, when high availability is employed. On the command line, separate multiple host names by commas.
On UNIX systems, only the |
-addSubscriberHosts |
Adds spare hosts to the pool of subscriber hosts dynamically, when high availability is employed. On the command line, separate multiple host names by commas.
On UNIX systems, only the |
-beginAlterSchema |
Enables manual alteration, addition or dropping of cache groups to the active standby pair replication scheme when automatic include of new schema objects in the active standby pair scheme is not possible. Also, enables creation of PL/SQL procedures, sequences materialized views and indexes on tables with data. Enables addition of a read-only subscriber that is not managed by Oracle Clusterware. While adding objects to the schema, the active standby pair is brought down, but the active node stays attached if you are using grid.
See also: |
-create |
Creates the active standby pair replication scheme for the specified DSN and creates the associated action scripts.
This command:
|
-createVIPs |
Creates virtual IP addresses for the active standby pair. If no DSN is specified, displays the information of all active standby pairs managed under the same TimesTen instance administrator and TimesTen instance name managed by Oracle Clusterware. |
-delMasterHosts |
Deletes spare hosts to the pool of master hosts dynamically, when high availability is employed. On the command line, separate multiple host names by commas.
The command fails if the indicated hosts are not spare hosts. On UNIX systems, only the |
-delSubscriberHosts |
Deletes spare hosts to the pool of subscriber hosts dynamically, when high availability is employed. On the command line, separate multiple host names by commas.
The command fails if the indicated hosts are not spare hosts. On UNIX systems, only the |
-drop |
Drops the active standby pair replication scheme and deletes its action scripts. |
-dropVIPs |
Drops the virtual IP addresses for the active standby pair. |
-endAlterSchema |
Issued this option after an operation using the |
-h
|
Prints a usage message and exits. |
-init |
Starts the TimesTen cluster agent. |
-ocrConfig |
TimesTen cluster information is stored in the Oracle Cluster Registry (OCR). This option registers the admin user in the OCR. You must register the admin user once before performing any of the cluster initialization steps.
On UNIX and Linux systems, login as the On Windows systems, login as the instance administrator to run this command. You do not need to perform this step when starting an existing cluster that you have shutdown. |
-reauthenticate |
This command reauthenticates the user names and passwords after any of them have been modified. Even if only a single password is changed, this command still prompts for all user names and passwords.
For more details, see "Changing user names or passwords when using Oracle Clusterware" in the Oracle TimesTen In-Memory Database Replication Guide. |
-relocate |
Relocates the database from the local host to the next available spare host specified in the MasterHosts attribute in the cluster.oracle.ini configuration file. If no spare host is available, an error is returned.
If the database on the local host is active, roles are first reversed so that the remote standby store of the same cluster becomes active. The newly migrated database on the spare host always comes up as the standby database.This is useful to forcefully relocate a database if you must take the host offline, when high availability is employed. This command fails when basic High Availability (HA) is deployed for the same cluster. |
-restore |
Restores the active master database from the backup specified by RepBackupDir. Do not use this command when AutoRecover is enabled. |
-shutdown |
Stops the TimesTen cluster agent. |
-start [-noapp] |
Starts the cluster active standby pair. This results in starting all of the agents on the active database, creation of the standby database and the subscriber databases (if they exist) through duplicate if necessary, and subsequent starting of all agents on those databases. If you specify -noapp, the applications are not started. You can use the -startapps option to start the applications later. |
-startapps |
Starts the applications in the cluster. |
-stopapps |
Stops the applications in the cluster. |
-status |
Obtains the status of resources in the cluster. |
-stop |
Stops the replication agent and the cache agent and disconnects the application from both databases of an active standby pair. Also automatically detaches a grid member from a cache grid that is managed by Oracle Clusterware. |
-switch |
Reverses the role of an active standby pair in a cluster. The standby database becomes the new active, while the existing active database becomes the standby database. |
-timeout seconds |
Specifies a timeout value for the -switch option. Specify an integer value greater than 0. The default is 900 seconds.
If you enter an invalid value, TimesTen uses the default value of If the timeout expires, TimesTen returns an error message and fails to verify the standby database. |
-dsn DSN |
Specifies the DSN for the active standby pair. |
-hosts "host_name1, host_name2[, ...]" |
Specifies the hosts on which to start or shut down the TimesTen cluster agent. If this option is not specified, the TimesTen cluster agent is started or stopped on all hosts. |
-ttclusterini path |
Specifies the full path name of the cluster.oracle.ini file. The default location is in the daemon home directory. The default location is recommended. |
-V | -version |
Prints the release number of ttCWAdmin and exits. |
To create and start an active standby pair managed by Oracle Clusterware, using the clusterDSN DSN, enter:
ttCWAdmin -create -dsn clusterDSN ttCWAdmin -start -dsn clusterDSN
To stop and drop an active standby pair managed by Oracle Clusterware, using the clusterDSN DSN, enter:
ttCWAdmin -stop -dsn clusterDSN ttCWAdmin -drop -dsn clusterDSN
When you use Oracle Clusterware with TimesTen, you cannot use these commands and SQL statements:
CREATE ACTIVE STANDBY PAIR, ALTER ACTIVE STANDBY PAIR and DROP ACTIVE STANDBY PAIR SQL statements.
The -cacheStart and -cacheStop options of the ttAdmin utility after the active standby pair has been created.
The -duplicate option of the ttRepAdmin utility.
The ttRepStart and ttRepStop built-in procedures.
Built-in procedures for managing a cache grid when the active standby pair in a cluster is a member of a grid.
The -repStart and -repStop options of the ttAdmin utility.
In addition, do not call ttDaemonAdmin -stop before calling ttCWAdmin -shutdown.
The TimesTen integration with Oracle Clusterware accomplishes these operations with the ttCWAdmin utility and the attributes in the cluster.oracle.ini file.
ttDaemonAdmin {-h | -help | -?}
ttDaemonAdmin {-V | -version}
ttDaemonAdmin [-force] {-start | -stop | -restart}
ttDaemonAdmin [-startserver | -restartserver]
ttDaemonAdmin [-force] -stopserver
ttDaemonAdmin -verbose
ttDaemonAdmin has the options:
| Option | Description |
|---|---|
-h
|
Prints a usage message and exits. |
-force |
Starts or stops the TimesTen main daemon, even when warnings are returned or with -stopserver immediately stops the server processes. |
-restart |
Restarts the TimesTen main daemon. |
-restartserver |
Restarts the TimesTen Server. |
-start |
Starts the TimesTen main daemon. |
-startserver |
Starts the TimesTen Server daemon. |
-stop |
Stops the TimesTen main daemon. |
-stopserver |
Stops the TimesTen Server daemon.
Without the With the |
-V | -version |
Prints the release number of ttDaemonAdmin and exits. |
Changes to the TimesTen Server options are temporary. To permanently set or disable the TimesTen Server options, you must change the options in the ttendaemon.options file.
Use the -force option with caution, as it may leave databases in a state where you must perform recovery procedures.
When you use this utility on Windows Vista, you must be running with Windows Administrative privileges.When you stop the daemon (ttDaemonAdmin -stop), first stop all application connections to the database. This includes stopping the replication agent and the cache agent, if they are running. This decreases startup time when the daemon is restarted. In addition, not stopping application connections or agents can result in the database becoming in validated.
If the Oracle Clusterware agent is running, you must stop it on the local host before stopping the TimesTen main daemon (ttDaemonAdmin -stop). If you do not stop the Clusterware agent, the main daemon stops temporarily with this command, but then restarts. To stop the Oracle Clusterware agent, use:
ttcwadmin -shutdown -hosts localhost
When you use this utility to restart the server, the TimesTen daemon reads the ttendaemon.options files to see if it has been changed since it was last read. If the file has been changed, TimesTen checks for the values of the options:
-server -serverShmIpc -serverShmSize -noserverlog
ttendaemon.options file, see "Managing TimesTen daemon options" in Oracle TimesTen In-Memory Database Operations Guide.The TimesTen daemon (referred to as the TimesTen Data Manager Service on Windows) and its subdaemons and agents write error and status messages to the following daemon logs:
A user error log that contains information you should be aware of, including actions you may need to take
A support log containing everything in the user error log plus information of use by TimesTen Customer Support
The ttDaemonLog utility enables you to do the following:
Control the types of events and categories of messages that are reported in the user error log.
Display all messages or selected categories of messages from the log to the standard output.
ttDaemonLog {-h | -help | -?}
ttDaemonLog {-V | -version}
ttdaemonLog [-show type] [-b | -r | -s] [-f] [-maxlines]
[-loglevel level [DSN | -connstr connStr]]
[-[no]logcomponent component [DSN | -connstr connStr]]
[-logreset] [-msg messagestring] [-setquiet | -setverbose]
[-file filename] [-facility name]
[-n computer]
Notes:
The -file and -facility options apply only on UNIX.
The -n option applies only on Windows and is not relevant in typical usage.
ttDaemonLog has the options:
| Option | Description |
|---|---|
-b |
Prints all TimesTen-generated log entries. |
-f |
When the end of the log is reached, ttDaemonLog does not terminate but continues to execute, periodically polling the log to retrieve and display additional TimesTen log records. This is useful, for example, for generating a display of log data that is updated in real time. |
-facility name |
Specifies the syslog facility name being used.
Note: This option applies only on UNIX. |
-file filename |
Specifies the file into which TimesTen logs messages.
If not specified, examine the system's Note: This option applies only on UNIX. |
-h
|
Shows ttDaemonLog usage information and exits. |
-maxlines |
Maximum number of lines at end of the log to display Defaults to 40 lines if -f is specified. If 0 is specified, there is no maximum. |
-logcomponent component
|
By default, all categories of messages are logged, but you can use -logcomponent to specify a category to be logged, or -nologcomponent to specify a category to not be logged. You can specify only a single component, but can run ttDaemonLog with these options multiple times to determine the desired set of messages.
If a DSN or connection string is specified, the option applies only to the specified database. You can run Supported categories are:
|
-loglevel level |
Specifies a cutoff for the level of messages that are logged in the support log. A lower value results in fewer messages. (For example, if you specify level 5, messages of level 1, 2, 3, 4, or 5 would be logged.) This option is typically relevant only for Customer Support use.
If a DSN or connection string is specified, the option applies only to that database. |
-logreset |
Resets event logging parameters. |
-msg messagestring |
Inserts the specified text into the TimesTen user log. |
-n computer |
Displays the log from a different computer. Specify the Universal Naming Convention (UNC) name of the target computer.
Note: This option applies only on Windows and only if you are using the Windows Event Log for TimesTen logging, which is not typical usage. |
-r |
Prints only the TimesTen replication agent log. (Same as -show replication.) |
-s |
Prints only the TimesTen Server log. (Same as -show server.) |
-setverbose
|
Enables (-setverbose) or disables (-setquiet) TimesTen verbose logging. |
-show type |
When you use ttDaemonLog to display log messages to the standard output, you can use the -show option with one of the following types to limit the displayed log messages to that type only:
Note: You cannot show a category whose logging has been disabled through |
-V | -version |
Prints the release number of ttDaemonLog and exits. |
By default, the ttDaemonLog utility logs messages and errors from all the TimesTen components. You can narrow the scope of what is written to the log by setting the -nologcomponent option. This option can be applied to selected databases or all databases.
To display all the output from the TimesTen daemon and server on your local computer:
ttDaemonLog
To prevent messages and errors related to replication for all databases from being written to the log:
ttDaemonLog -nologcomponent replication
To prevent messages and errors related to replication for the masterdsn database from being written to the log:
ttDaemonLog -nologcomponent replication masterdsn
To prevent both replication and TimesTen Cache errors and messages from being written:
ttDaemonLog -nologcomponent replication ttDaemonLog -nologcomponent cache
If, after disabling a component through the -nologcomponent option, you want to re-enable it, you can use the -logcomponent option. For example, after disabling messages for replication and TimesTen Cache as shown in the preceding example, you can re-enable replication messages as follows:
ttDaemonLog -logcomponent replication
To re-enable logging for all TimesTen components, use the -logreset option:
ttDaemonLog -logreset
The TimesTen Server generates a message each time an application connects to or disconnects from a client DSN if these messages were specified to be generated during installation. To display just the server log messages:
ttDaemonLog -show server
To display just the replication agent messages:
ttDaemonLog -show replication
To display just the cache agent messages:
ttDaemonLog -show cache
To display all messages from the TimesTen processes:
ttDaemonLog -show all
To restore logging to its default "verbose" level, use the -setverbose option:
ttDaemonLog -setverbose
On UNIX, to write the log output to the file /var/adm/syslog/syslog.log:
ttDaemonLog -file /var/adm/syslog/syslog.log
On UNIX, to direct logging to the local7 facility:
ttDaemonLog -facility local7
While primarily intended for use by TimesTen Customer Support, this information may be useful to system administrators and developers.
This utility is supported only where the TimesTen Data Manager is installed.
To permanently set or disable verbose logging, change the options in the ttendaemon.options file. See "Modifying informational messages" in the Oracle TimesTen In-Memory Database Operations Guide.
Destroys a database including all checkpoint files, transaction logs and daemon catalog entries (though not the DSNs).
ttDestroy {-h | -help | -?}
ttDestroy {-V | -version}
ttDestroy [[-wait] [-timeout secs]] [-force] {-connStr connection_string |
DSN | dspath}
ttDestroy has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be destroyed. |
dspath |
The fully qualified name of the database to be destroyed.
This is not the DSN associated with the connection but the fully qualified database path name associated with the database as specified in the For example, for a database consisting of files |
-h
|
Prints a usage message and exits. |
-force |
Destroy even if files are from an incompatible version or a different instance of TimesTen. |
-timeout seconds |
Indicates the time in seconds that ttDestroy should wait. If no timeout value is supplied, TimesTen waits five seconds before retrying the destroy operation. |
-V | -version |
Prints the release number of ttDestroy and exits. |
-wait |
Causes ttDestroy to continually retry the destroy operation until it is successful, in those situations where the destroy fails due to some temporary condition, such as when the database is in use. |
Using ttDestroy is the only way to delete a database completely and safely. Do not remove database checkpoint or transaction log files manually.
This utility is supported only where the TimesTen Data Manager is installed.
In the case that the database to be destroyed is part of a cache grid, ttDestroy performs a detaches the database from the grid.
ttDestroy does not perform cleanup of Oracle database objects from autorefresh or AWT cache groups. If there are autorefresh or AWT cache groups in the database, execute the cachecleanup.sql script to clean up the cache objects in the Oracle database for that particular database, to generate Oracle SQL to perform cleanup after the database has been destroyed.
You can execute SQL statements and call TimesTen built-in procedures from ttIsql. You can execute SQL interactively from the command line. For a detailed description on running SQL from ttIsql, use the -helpfull option. In addition, you can call a TimesTen built-in procedure with call procedure-name.
The ttIsql command attempts to cancel an ongoing ODBC function when the user presses Ctrl-C.
On UNIX, this utility is supported for TimesTen Data Manager DSNs. Use ttIsqlCS for client/server DSNs.
The ttIsql utility starts with AUTOCOMMIT turned on, even when running a script. You can turn AUTOCOMMIT off and back on as necessary.
For more details on the ttIsql utility, see the chapter "Using the ttIsql Utility" in the Oracle TimesTen In-Memory Database Operations Guide
ttIsql {-h | -help | -? | -helpcmds | - helpfull}
ttIsql {-V | -version}
ttIsql [-f inputFile] [-v verbosity] [-e commands | sql_statement]
[-interactive] [-N ncharEncoding] [-wait] {-connStr connection_string | DSN}
ttIsql has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be connected. |
-e commands |
Specifies a semicolon separated list of ttIsql commands to execute on startup. |
-f filename |
Read SQL statements from filename. |
-h
-? |
Prints a usage message and exits. |
-helpcmds |
Prints a short list of the interactive commands. |
-helpfull |
Prints a full description of the interactive commands. |
-interactive |
Forces interactive mode. This is useful when running from an emacs comint buffer. |
-N ncharEncoding |
Specifies the character encoding method for NCHAR output.
Valid values are If no value is specified, TimesTen uses the system's native language characters. |
-V | -version |
Prints the release number of ttIsql and exits. |
-v verbosity |
Specifies the verbosity level. One of:
|
-wait |
Waits until successful connect. |
Also see the list of ttIsql "Set/show attributes".
Boolean commands can accept the values "ON" and "OFF" or "1" and "0".
ttIsql has the commands:
| Command | Description |
|---|---|
accept variable[NUM[BER]| CHAR |BINARY_FLOAT | BINARY_DOUBLE] [DEF[AULT]default_value] [PROMPT prompt_text | NOPR[OMPT]] [HIDE] |
Gets input from a user and DEFINES the variable. If a type is specified then it validates for that type. The default (enclosed in quotes) is assigned if the user just presses enter. The prompt is displayed before waiting for input (or can be suppressed). The HIDE option stops the terminal from displaying the entered text (for passwords).
The prompt is displayed before waiting for input, if specified without the |
allfunctions [[owner_name_pattern.] table_name_pattern] |
Lists, in a single column, the names of all the PL/SQL functions that match the given pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists PL/SQL functions matching the pattern in the Oracle database. See the |
allindexes [[owner_name_pattern.] table_name_pattern] |
Describes the indexes that it finds on the tables that match the input pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the patterns default to "%".
If passthrough is enabled, lists indexes on tables matching the pattern in the Oracle database. See the |
allpackages [[owner_name_pattern.] table_name_pattern] |
Lists, in a single column, the names of all the PL/SQL packages that match the given pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the patterns default to "%".
If passthrough is enabled, lists PL/SQL packages matching the pattern in the Oracle database. See the |
allprocedures [[owner_name_pattern.] procedure_name_ pattern] |
Lists, in a single column, the names of all the PL/SQL procedures that match the given pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists PL/SQL procedures matching the pattern in the Oracle database. See the |
allsequences [[owner_name_pattern.] table_name_pattern]] |
Lists, in a single column, the names of all the sequences that match the given pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists sequences on tables matching the pattern in the Oracle database. See the |
allsynonyms [[schema_pattern.] object_pattern]] |
Lists, in a single column, the names of all synonyms that match the given pattern. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists synonyms on tables matching the pattern in the Oracle database. See the |
alltables [[owner_name_pattern.] table_name_pattern]] |
Lists, in a single column, the names of all the tables that match the given pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists tables matching the pattern in the Oracle database. See the |
allviews [[owner_name_pattern.] view_name_pattern]] |
Lists, in a single column, the names of all the views that match the specified pattern selected from SYS.ALL_OBJECTS. When a pattern is missing, the pattern defaults to "%".
If passthrough is enabled, lists views matching the pattern in the Oracle database. See the |
builtins [builtin_name_ pattern] |
Lists, in a single column, the names of all the TimesTen built-in procedures that match the given pattern. When the pattern is missing, the pattern defaults to "%".
See the |
bye
|
Exits ttIsql. |
cachegroups [[cache_group_owner_pattern. cache_group_name_pattern]] |
Reports information on cache groups defined in the currently connected data source, including the state of any terminated databases that contain autorefresh cache groups.
If the optional argument is not specified then information on all cache groups in the current data source is reported. |
clearhistory |
Clears the history buffer. Also see history and savehistory. |
clienttimeout
|
Sets the client timeout value in seconds for the current connection. If no value is specified, displays the current value. |
cachesqlget
|
Generates an Oracle SQL*Plus compatible script for the installation or uninstallation of Oracle database objects associated with a readonly cache group, a user managed cache group with incremental autorefresh or an AWT cache group.
If If If the optional |
close [connect_id.] command_id]
|
Closes the prepared command identified by connection name connect_id and command ID command_id. If command_id is not specified, closes the most recent command. If closeall is selected, closes all currently open prepared commands. |
cmdcache [[by{sqlcmdid |querytext|owner}] query_subsstring] |
Displays the contents of the TimesTen SQL command cache.
Specify the If passthrough is enabled, the command ID is not passed through to the Oracle database. |
commit |
Commits the current transaction (durably if DurableCommits=1 for the connection). |
commitdurable |
Commits the current transaction durably. |
compact |
Compacts the database. |
compare varA VarB |
Compares the values of two variables and reports if they are different. The first difference is reported. |
connect[connection_string |[[DSN][as]connid [adding] [connection_string | DSN][as connid] |
Connects to the database with the specified ODBC connection_string.
If no password is supplied in this format, If no user is given, If When |
createandloadfromoraquery [owner_name.]table_name [num_threads] query |
Takes a table name, the number of threads for parallel load and an Oracle SELECT statement.
Creates the table in TimesTen if the table does not exist. Then, loads the table with the query result from the Oracle database. If the command creates the table, the table column names and types are derived from the query result. Notes:
Required Privileges: Requires |
define name [= value] |
Defines a string substitution alias.
If no value is provided, You must |
describe [[owner_pattern.] name_pattern | procedure_name_pattern |sql_statement | [connect_id.]command_id |*] |
List information on tables, synonyms, views, materialized views, materialized view logs, sequences, cache groups, PL/SQL functions, PL/SQL procedures, PL/SQL packages and TimesTen built-in procedures in that order when the argument is [owner_pattern.]name_pattern. Otherwise lists the specific objects that match the given pattern.
Describes the parameters and results columns when the argument is If If If the table being described is a materialized view log, the message lists the name of the materialized view for which the table is a log. If the table being described has a materialized view log on it, the message indicates the name of the materialized view log. When describing cache groups, reports information on cache groups defined in the currently connected data source, including the state of any terminated databases that contain autorefresh cache groups. The command alias is |
disconnect [all] |
Disconnects from the database. If all is specified, disconnects and closes all connections. When disconnect finishes, the current connection is set to the reserved connection named "none." |
dssize [k|m|g|t] |
Prints database size information in KB, MB, GB or TB. The default is KB. The output indicates the unit returned. |
e: msg
|
Echoes the specified messages, terminated by the end of the line. A semicolon is not required to end the line. Messages are not echoed if verbosity is set to 0. |
edit [ file | !history_search_command ] |
You can use the ttIsql edit command to edit a file or edit ttIsql commands in a text editor. The ttIsql edit command starts a text editor such as emacs, gedit, or vi.
If TimesTen does not find an exact file match for the specified You can edit a SQL statement that is stored in the history list of the current If you execute the You can only use one parameter at a time. The You can specify the default editor by defining the Command> DEFINE _EDITOR=vi If you do not define the For more details, see "Using the ttIsql edit command" in the Oracle TimesTen In-Memory Database Operations Guide. |
exec [connect_id.] command_id] | PLSQLSTMT |
Executes the prepared command command_id o
n connection The If no argument is supplied, executes the most recent command. |
execandfetch [connect_id.]command_id] |
Executes and fetches all results from prepared command command_id on connection connect_id. If command_id is not specified, executes and fetches all results from the most recent command. |
explain [plan for] {[ Connid.]ttisqlcmdid | sqlcmdid sqlcmdid | sqlstmt |!history} |
Explains the plan for the specified SQL statement, including prepared ttIsql statements, specified in the ttisqlcmdid argument, or the sqlcmdid argument.
A digit that is not qualified with the If passthrough is enabled, the command ID is not passed through to the Oracle database. |
fetchall [connect_id.]command_id] |
Fetches all results from prepared command command_id on connection connect_id.
If |
fetchone [connect_id.]command_id] |
Fetches one result from prepared command command_id on connection connect_id.
If |
free [connect_id.] command_id] |
Frees prepared command command_id on connection connect_id.
If no command is specified, frees the most recent command. |
functions [object_name_pattern] |
Lists, in a single column, the names of PL/SQL functions owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough is enabled, lists PL/SQL functions matching the pattern in the Oracle database. See the |
globalprocessing statement |
Runs the specified statement with global processing enabled.
You cannot specify the statement with the |
help [command [command ...]| all | comments | attributes] |
Prints brief or detailed help information for commands.
If specific commands are given as arguments then detailed help for each command is printed. If you do not know the exact name of a command, try typing just a few characters that may be part of the command name. If If If If no argument is given then brief help information for all commands is printed. |
history
[ |
Lists previously executed commands.
The If the The history list stores up to 100 of the most recently executed commands. Use the See the |
host os_command |
Executes an operating system command. The command is executed in the same console as ttIsql.
This command sets the environment variable The value of the variable is the connection string of the current connection. To see the exit status of the command, use the |
if-then-else |
The if-then-else command construct enables you to implement conditional branching logic in a ttIsql session. For more details, see "Syntax for the IF-THEN-ELSE command construct". |
indexes [table_name_pattern] |
Describes the indexes that it finds on the tables owned by the current user that match the input pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough is enabled, lists indexes on tables matching the pattern in the Oracle database. See the |
monitor [optional_monitor_column] |
Formats the contents of the SYS.MONITOR table for easy viewing.
If the |
packages [object_name_pattern] |
Lists, in a single column, the names of PL/SQL packages owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough is enabled, lists PL/SQL packages matching the pattern in the Oracle database. See the |
prepare [[connid.]command_id]SQL_Statement |
Prepares the specified SQL statement. If the command_id argument is not specified the command_id is assigned automatically.
The |
print [variable] |
Prints the value of the specified bind variable or all variables if no variable is specified. If the variable is a REF CURSOR, then the results are fetched and printed. |
procedures [procedure_name_ pattern] |
Lists, in a single column, the names of PL/SQL procedures owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough is enabled, lists PL/SQL procedures matching the pattern in the Oracle database. See the |
quit |
Exits ttIsql. |
remark msg |
Specifies that the message on the line should be treated as a comment. When rem or remark is the first word on the line, ttIsql reads the line and ignores it. |
repschemes [[scheme_owner_pattern.] scheme_name_pattern] |
Reports information on replication schemes defined in the currently connected data source. This information describes all elements associated with the replication schemes.
If the optional argument is not specified then information on all replication schemes defined in the current data source is reported. |
retryconnect [0|1] |
Disables(0) or enables(1) the wait for connection retry feature.
If the connection retry feature is enabled then connection attempts to a data source that initially fail due to a temporary situation are retried until the connection attempt succeeds. For example, if data source recovery is in progress when attempting to connect, the connection retry feature causes the connect command to continue to attempt a connection until the recovery process is complete. If the optional argument is omitted then the connection retry feature is enabled by default. |
rollback |
Rolls back the current transaction. AutoCommit must be off. This command does not stop TimesTen Cache operations on the Oracle database, including passthrough statements, flushing, manual loading, manual refreshing, synchronous writethrough, propagating and dynamic loading. |
rpad varname desiredlength paddingstring |
The RPAD command acts like the SQL function RPAD()with some limitations:
Only variables that are character based ( |
run filename [arguments]|
|
Reads and executes SQL commands from filename. The run command can be nested up to five levels.
The When you specify See "Example parameters of command string substitution" for a description of |
savehistory
|
Writes the history buffer to the specified output file.
Only command, no parameter values are saved in the output file. Therefore, a script may not be able to replay the history from the output file. If the If If See the |
sequences [sequence_name_pattern] |
Lists, in a single column, the names of sequences owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough is enabled, lists sequences on tables matching the pattern in the Oracle database. See the |
set attribute [value] |
Sets the specified set/show attribute to the specified value.
If no value is specified, displays the current value of the specified attribute. For a description of accepted attributes, see "Set/show attributes". |
setjoinorder tblNames [...] |
Specifies the join order for the optimizer. AutoCommit must be off. |
setuseindex index_name,correlation_name,
|
Sets the index hint for the query optimizer. |
setvariable variable_name := value |
Sets the value of a scalar bind variable or an element of an array bind variable. For example: setvariable myvar := 'TimesTen'; There must be a space on either side of the assignment operator (:=).
For more information, see "Declaring and setting bind variables" in the Oracle TimesTen In-Memory Database Operations Guide. |
show {all | attribute} |
Displays the value for the specified set/show attribute or displays all the attributes.
For a description of accepted attributes, see "Set/show attributes". |
showjoinorder {0 | 1} |
Enables or disables the storing of join orders.
Call the |
sleep [n] |
Suspends execution for n seconds. If n is not specified then execution is suspended for 1 second. |
spool filename [option | OFF] |
Writes a copy of the terminal output to the file filename.
If you do not provide an extension to
When you specify the value If you specify a spool command while one is running, the active spool is closed and a new files is opened. |
sqlcolumns [owner_name_pattern.]table_name_pattern |
Prints results of an ODBC call to SQLColumns. |
sqlgetinfo infotype |
Prints results of an ODBC call to SQLGetInfo. |
sqlstatistics [[owner_name_pattern.]table_name_pattern] |
Prints results of an ODBC call to SQLStatistics. |
sqltables[[owner_name_pattern.]table_name_pattern] |
Prints results of a call to SQLTables. The pattern is a string containing an underscore ( _ ) to match any single character or a percent sign (%) to match zero or more characters. |
statsclear [[owner_name.]table_name] |
Clears statistics for specified table (or all tables if no table is specified). |
statsestimate [[owner_name.]table_name] {n rows | p percent} |
Estimates statistics for specified table (or all tables if no table is specified).
If you estimate statistics with an empty table list, statistics on system tables are updated also, if you have privileges to update the system tables. |
statsupdate [[owner_name_pattern.] table_name_pattern] |
Updates statistics for specified table (or all tables if no table is specified).
If |
synonyms [[schema_pattern.] object_pattern]] |
Lists, in a single column, the names of synonyms owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough to an Oracle database is enabled, lists synonyms on tables matching the pattern in the Oracle database. See the |
tables [table_name_pattern]] |
Lists, in a single column, the names of tables owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to %.
If passthrough to an Oracle database is enabled, lists tables matching the pattern in the Oracle database. See the |
tablesize [[owner_name_pattern.] table_name_pattern]] |
For each table that matches the pattern, lists the contents of the ALL_TAB_SIZES view.
See the |
tryglobalprocessing [0|1] |
Disables (0) or enables (1) the global processing of eligible queries in the cache grid. If the optional argument is omitted, global processing is enabled. Use show optprofile to query GlobalProcessing.
|
undefine name |
Undefines a string substitution alias. |
unsetjoinorder |
Clears join order advice to optimizer. AutoCommit must be off. |
unsetuseindex |
Clears the index hint for the query optimizer. |
use [conn_id] |
Displays the list of current connections and their IDs. If connid is specified, switches to the given connection ID.
To use the name of the first connection, you can specify If See the |
variable [variable_name [data_type] [:= value]]
The syntax for binding multiple values to an array using the variable array_name '[' array_size ']' data_type(n):= '[' value1, ... valuex ']' |
Declares a bind variable that can be referenced in a statement or displays the definition of the variable if the type is missing. Type can be one of the following: (n), NUMBER, CHAR(n), NCHAR(n), VARCHAR2(n), NVARCHAR2(n), BLOB, CLOB, NCLOB, or REFCURSOR. If only (n) is supplied, it is assumed to be VARCHAR2 (n).
Assigns a value to a single variable or multiple values if the data type is an array. You can assign a value later with the For more information, see "Declaring and setting bind variables" in the Oracle TimesTen In-Memory Database Operations Guide. |
version |
Reports version information. |
views [table_name_pattern] |
Lists, in a single column, the names of views owned by the current user that match the given pattern. When a name pattern is missing, the pattern defaults to "%".
If passthrough to an Oracle database is enabled, lists views matching the pattern in the Oracle database. See the |
waitfor expected_result timeoutseconds sqlstatement |
Runs the given statement once a second until the query returns the expected result or a timeout occurs. The query must have only one column and must return exactly one row. Any errors in the query terminate the loop. |
waitforresult expected_result timeoutseconds searchrow searchcol sqlstatement |
Similar to the waitfor command, except that the result can have 1 or more columns. Also, the result can return 0 rows.
Runs the given statement once a second until the query returns the expected result or a timeout occurs. The |
whenever sqlerror |
Provide direction on how to handle errors when in ttIsql. For more details, see "Syntax for the WHENEVER SQLERROR command". |
xlabookmarkdelete id |
Deletes a persistent XLA bookmark.
If a bookmark to delete is not specified then the status of all current XLA bookmarks is reported. Also see "ttXlaDeleteBookmark" in Oracle TimesTen In-Memory Database C Developer's Guide. Requires |
Syntax for the IF-THEN-ELSE command construct
This section provides the syntax for the IF-THEN-ELSE construct. For more details on using the IF-THEN-ELSE command construct, see "Conditional control with the IF-THEN-ELSE command construct" in the Oracle TimesTen In-Memory Database Operations Guide.
IF [NOT]
{ Literal1 | :BindVariable1 }
{ = | IN }
{ Literal2 | :BindVariable2 | SelectStatement }
THEN "ThenCommands"
[ ELSE "ElseCommands" ] ;
The ttIsql IF-THEN-ELSE command has the parameters:
| Parameter | Description |
|---|---|
IF |
The IF command must end in a semicolon (;).
The |
NOT |
Using NOT reverses the desired result of the condition. |
Literal1, Literal2 |
A value that can be part of a comparison. |
BindVariable1, BindVariable2 |
A bind variable is equivalent to a parameter. You can use the :BindVariable1 notation for passing bind variables into this construct. The variable can be created and set using the variable or setvariable ttIsql commands. |
= | IN |
You can use the IN operator only with the SelectStatement. You can use the IN operator with zero or more returned rows. You can use the equal (=) operator only with a single returned row. |
SelectStatement |
A provided SELECT statement must start with SELECT. The SELECT statement can return only one column. In addition, it can return only one row when the equal (=) operator is provided.
The |
ThenCommands, ElseCommands |
All commands in the THEN or ELSE clauses must be delimited by a semicolon and cannot contain embedded double quotes. These clauses can conditionally execute ttIsql commands, such as host or run, which cannot be executed through PL/SQL. You can use the CALL statement within the THEN or ELSE clauses. You cannot use PL/SQL blocks. |
Restrictions for the IF-THEN-ELSE construct are as follows:
You cannot compare variables of the LOB data type.
The values are compared case-sensitive with strcmp. A character padded value might not match a VARCHAR2 because of the padding.
Syntax for the WHENEVER SQLERROR command
Execute the WHENEVER SQLERROR command to prescribe what to do when a SQL error occurs. For more details and examples on how to use the WHENEVER SQLERROR command, see "Error recovery with the WHENEVER SQLERROR" command in the Oracle TimesTen In-Memory Database Operations Guide.
WHENEVER SQLERROR { ExitClause | ContinueClause | SUPPRESS |
SLEEP Number | ExecuteClause }
When you specify EXIT, always exit ttIsql if an error occurs. ExitClause is as follows:
EXIT [ SUCCESS | FAILURE | WARNING | Number | :BindVariable ] [ COMMIT | COMMIT ALL | ROLLBACK ]
When you specify CONTINUE, ttIsql continues to the next command, even if an error occurs. ContinueClause is as follows:
CONTINUE [ COMMIT | COMMIT ALL | ROLLBACK | NONE ]
Execute specified commands before continuing. ExecuteClause is as follows:
EXECUTE "Cmd1;Cmd2;...;"
The WHENEVER SQLERROR command options are as follows:
EXIT: Always exit ttIsql if an error occurs. Specify what is performed before ttIsql exits with one of the following. SUCCESS is the default option for EXIT.
SUCCESS or FAILURE or WARNING: Return SUCCESS (value 0), FAILURE (value 1), or WARNING (value 2) to the operating system after ttIsql exits for any SQL error.
Number: Specify a number from 0 to 255 that is returned to the operating system as a return code. Once ttIsql exits, you can retrieve the error return code with the appropriate operating system commands. For example, use echo $status in the C shell (csh) or echo $? in the Bourne shell (sh) to display the return code.
The return code can be retrieved and processed within batch command files to programmatically detect and respond to unexpected events.
:BindVariable: Returns the value in a bind variable that was previously created in ttIsql with the variable command. The value of the variable at the time of the error is returned to the operating system in the same manner as the Number option.
Note:
The bind variable used within theWHENEVER SQLERROR command cannot be defined as a LOB, REFCURSOR, or any array data type.In addition, you can specify whether to commit or rollback all changes before exiting ttIsql.
COMMIT: Executes a COMMIT and saves changes only in the current connection before exiting. The other connections exit with the normal disconnect processing, which rolls back any uncommitted changes.
COMMIT ALL: Executes a COMMIT and saves changes in all connections before exiting.
ROLLBACK: Before exiting, executes a ROLLBACK and abandons changes in the current connection and, by default, in all other connections. The other connections exit with the normal disconnect processing, which automatically rolls back any uncommitted changes.
CONTINUE: Do not exit if an error occurs. The SQL error is displayed, but the error does not cause ttIsql to exit. The following options enable you to specify what is done before continuing to the next ttIsql command:
NONE: This is the default. Take no action before continuing.
COMMIT: Executes a COMMIT and saves changes in the current connection before continuing.
COMMIT ALL: Executes a COMMIT and saves changes in all connections before continuing.
ROLLBACK: Before continuing, executes a ROLLBACK and abandons changes in the current connection and, by default, in all other connections. The other connections exit with the normal disconnect processing, which automatically rolls back any uncommitted changes.
SUPPRESS: Do not show any error messages and continue.
SLEEP: Sleep for a specified number of seconds before continuing.
EXECUTE: Execute specified commands before continuing. Each command is separated from the other commands by a semicolon (;). If any command triggers additional errors, those errors may cause additional actions that could potentially result in a looping condition.
Also see the list of ttIsql "Commands". Some commands appear here as attributes of the set command. In that case, you can use them with or without the set command.
Boolean attributes can accept the values "ON" and "OFF" or "1" and "0".
The ttIsql set command has the attributes:
| Attribute | Description |
|---|---|
all |
With show command only. Displays the setting of all the ttIsql commands. |
autocommit [1|0] |
Turns AutoCommit off and on. If no argument is given, displays the current setting. |
autovariables [1|0] |
Turns autovariables off and on. TimesTen creates an automatic bind variable with the same name as each column in the last fetched row. You can use an automatic bind variable in the same manner of any bind variable. For more information, see "Automatically creating bind variables for retrieved columns" in the Oracle TimesTen In-Memory Database Operations Guide. |
columnlabels [0 | 1] |
Turns the columnlabels feature off (0) or on (1).
If no argument is specified, the current value of The initial value of When the value is on ( You can also enable this attribute without specifying the |
connstr |
Prints the connection string returned from the driver from the SQLDriverConnect call. This is the same string printed when ttIsql successfully connects to a database. |
define [&|c|on|off] |
Sets the character used to prefix substitution variables to c.
Default value for |
dynamicloadenable [on|off] |
Enables or disables dynamic load of data from an Oracle database to a TimesTen dynamic cache group. By default, dynamic load of data from an Oracle database is enabled. |
echo [on | off] |
With the set command, prints the commands listed in a run, @ or @@ script to the terminal as they are executed.
If |
editline [0 | 1] |
Turns the editline function off and on. By default, editline is on.
If |
err | error |errors [.objecttype[schema.] name] |
With the show command, displays error information about the given PL/SQL object.If no object type or object name is supplied, ttIsql assumes the PL/SQL object that you last attempted to create and retrieves the errors for that object. If no errors associated with the given object are found, or there was no previous PL/SQL DDL, then ttIsql displays "No errors." |
feedback [on | off] rows |
Controls the display of status messages after statement execution.
When |
isolation [{READ_COMMITTED | 1}| {SERIALIZABLE | 0}] |
Sets isolation level. If no argument is supplied, displays the current value.
You can also enable this attribute without specifying the |
loboffset n |
Specifies the offset into the LOB that ttIsql should use as the starting point when it prints the resulting value of a LOB. For example if the value of the LOB is ABCEDFG, and the offset is 4, ttIsql prints DEFG, skipping the first 3 bytes.
The behavior is the same as |
long n |
Reports or controls the maximum number of characters for CLOB or BLOB data or the maximum number of bytes for BLOB data that are displayed when fetched or printed.
The default value is The command setting is valid for all connections in a session. |
longchunksize n |
Specifies the size of the chunk that ttIsql uses to get LOB data. |
multipleconnections [1 | ON] mc [1 | ON] |
Reports or enables handling of multiple connections.By default, ttIsql enables the user to have one open connection at a time.
If the argument If no value is supplied, the command displays the value of the You can also enable this attribute without specifying the |
ncharencoding [encoding] |
Specifies the character encoding method for NCHAR output. Valid values are LOCALE or ASCII.
If no value is specified, TimesTen uses the system's native language characters. You can also enable this attribute without specifying the |
optfirstrow [1|0] |
Enables or disables First Row Optimization.
If the optional argument is omitted, First Row Optimization is enabled. You can also enable this attribute without specifying the |
optprofile |
Prints the current optimizer flag settings and join order.
This attribute cannot be used with the |
passthrough [0|1|2|3|4|5] |
Sets the TimesTen Cache passthrough level for the current transaction. Because AutoCommit must be off to execute this command, ttIsql temporarily turns off AutoCommit when setting the passthrough level.
If no optional argument is supplied, the current setting is displayed. After the transaction, the passthrough value is reset to the value defined in the connection string or in the DSN or the default setting if no value was supplied to either. You can also enable this attribute without specifying the set command. Note: Some Oracle objects may not be described by |
prefetchcount [prefetch_count_size] |
Sets the prefetch count size for the current connection. If the optional argument is omitted, the current prefetch count size is reported. Setting the prefetch count size can improve result set fetch performance. The prefetch_count_size argument can take an integer value between 0 and 128 inclusive.
When you set the prefetch count to You can also enable this attribute without specifying the |
prompt [string] |
Replaces the Command> prompt with the specified string.
To specify a prompt with spaces, you must quote the string. The leading and trailing quotes are removed. A prompt can have a string format specifier ( |
querythreshold [seconds] |
With the show command, displays the value of the Query Threshold first connection attribute.
With the Specify a value in seconds that indicates the number of seconds that a query can execute before TimesTen writes a warning to the support log or throws an SNMP trap. |
rowdelimiters [0|off] | [ {1|on} [begin [ end]]] |
Controls the row delimiters in result sets. When on, user queries have the row delimited with < and > unless begin and end are specified. Not all result sets are affected by this control.
The default is |
serveroutput [on | off] |
With the set command set to on, after each executed SQL statement, displays any available output. This output is available for debugging I/O purposes, if the PL/SQL DBMS_OUTPUT package is set to store the output so that it can be retrieved using this command.
The default is
|
showcurrenttime [1|true|on] | [0|false|off] |
Enable or disable printing of the current wall clock time. |
showplan [0 | 1] |
Enables (1) or disables (0) the display of plans for selects/updates/deletes in this transaction. If the argument is omitted, the display of plans is enabled. AutoCommit must be off.
You can also enable this attribute without specifying the |
sqlquerytimeout [seconds] |
Specifies the number of seconds to wait for a SQL statement to execute before returning to the application for all subsequent calls.
If no time or The value of You can also enable this attribute without specifying the set command. |
timing [1|0] |
Enables or disables printing of query timing.
You can also enable this attribute without specifying the |
tryhash [1|0] |
Enables or disables use of hash indexes by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
trymaterialize [1|0] |
Enables or disables materialization by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
trymergejoin [1|0] |
Enables or disables use of merge joins by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
trynestedloopjoin [1|0] |
Enables or disables use of nested loop joins by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
tryrowid [1|0] |
Enables or disables rowID scan hint by the optimizer at the transaction level. |
tryrowlocks [1|0] |
Enables or disables use of row-level locking by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
tryserial [1|0] |
Enables or disables use of serial scans by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
trytmphash [1|0] |
Enables or disables use of temporary hashes by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
trytbllocks [1|0] |
Enables or disables use of table-level locking by the optimizer at the transaction level. AutoCommit must be off.
You can also set this attribute without specifying the |
trytmptable [1|0] |
Enables or disables use of temporary tables by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the set command. |
trytmprange [1|0] |
Enables or disables use of temporary range indexes by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
tryrange [1|0] |
Enables or disables use of range indexes by the optimizer at the transaction level. AutoCommit must be off.
You can also enable this attribute without specifying the |
verbosity [level] |
Changes the verbosity level. The verbosity level argument can be an integer value of 0, 1, 2, 3 or 4. If the optional argument is omitted then the current verbosity level is reported.
You can also enable this attribute without specifying the |
vertical [{0 | off} | {1 | on} | statement] |
Sets or displays the current value of the vertical setting. The default value is 0 (off).
If statement is supplied, the command temporarily turns vertical on for the given statement. This form is only useful when the vertical flag is off. The You can also enable this attribute without specifying the |
The types of comment markers are:
# [comment_text] -- [comment_text] /* [comment_text] */
The C-style comments ( /* [comment_text] */) can span multiple lines.
The comments delimited by the
#
and the
-
characters should not span multiple lines. If a comment marker is encountered while processing a line, ttIsql ignores the remainder of the line.
'--' at the beginning of a line is considered a SQL comment. The line is considered a comment and no part of the line is included in the processing of the SQL statement. A line that begins with '--+' is interpreted as a segment of a SQL statement.
The comment markers can work in the middle of a line.
Example:
monitor; /*this is a comment after a ttIsql command*/
ttIsql implements a csh-like command history.
Command Usage: history [-r] [num_commands]
Description: Lists previously executed commands. The num_commands parameter specifies the number of commands to list. If the -r parameter is specified, commands are listed in reverse order.
Command Usage: ! [command_id|command_string| !]
Description: Executes a command in the history list. If a command_id argument is specified, the command in the history list associated with this ID is executed again. If the command_string argument is specified, the most recent command in the history list that begins with command_string is executed again. If the ! argument is specified then the most recently executed command is executed again.
Example: "!!;" -or- "!10;" -or- "!con;"
Also see the clearhistory, history, savehistory commands.
By default, ttIsql supports keystroke shortcuts when entering commands. To turn this feature off, use:
Command> set editline=0;
The ttIsql keystroke shortcuts are:
| Keystroke | Action |
|---|---|
| Left Arrow | Moves the insertion point left (back). |
| Right Arrow | Moves the insertion point right (forward). |
| Up Arrow | Scroll to the command before the one being displayed. Places the cursor at the end of the line. |
Up Arrow <RETURN> |
Scrolls to the PL/SQL block before the one being displayed. |
| Down Arrow | Scrolls to a more recent command history item and puts the cursor at the end of the line. |
Down Arrow <RETURN> |
Scrolls to the next PL/SQL block after the one being displayed. |
Ctrl-A |
Moves the insertion point to the beginning of the line. |
Ctrl-E |
Moves the insertion point to the end of the line. |
Ctrl-K |
"Kill" - Saves and erases the characters on the command line from the current position to the end of the line. |
Ctrl-Y |
"Yank"- Restores the characters previously saved and inserts them at the current insertion point. |
Ctrl-F |
Forward character - move forward one character. (See Right Arrow.) |
Ctrl-B |
Backward character - moved back one character. (See Left Arrow.) |
Ctrl-P |
Previous history. (See Up Arrow.) |
Ctrl-N |
Next history. (See Down Arrow.) |
With dynamic parameters, you are prompted for input for each parameter on a separate line. Values for parameters are specified the same way literals are specified in SQL.
SQL_TIMESTAMP columns can be added using dynamic parameters. (For example, values like '1998-09-08 12:1212').
Parameter values must be terminated with a semicolon character.
The possible types of values that can be entered are:
Numeric literals. Example: 1234.5
Time, date or timestamp literals within single quotation marks. Examples:
'12:30:00''2000-10-29''2000-10-29 12:30:00''2000-10-29 12:30:00.123456'
Unicode string literals within single quotation marks preceded by 'N'. Example: N'abc'
A NULL value. Example: NULL
The '*' character that indicates that the parameter input process should be stopped. Example: *
The '?' character prints the parameter input help information. Example: ?
Example parameters of command string substitution
Command> select * from dual where :a > 100 and :b < 100; Type '?' for help on entering parameter values. Type '*' to end prompting and abort the command. Type '-' to leave the parameter unbound. Type '/;' to leave the remaining parameters unbound and execute the command. Enter Parameter 1 'A' (NUMBER) > 110 Enter Parameter 2 'B' (NUMBER) > 99 < X > 1 row found. Command> var a number; Command> exec :a := 110; PL/SQL procedure successfully completed. Command> print a A : 110 Command> var b number; Command> exec :b := 99; PL/SQL procedure successfully completed. Command> select * from dual where :a > 100 and :b < 100; < X > 1 row found. Command> print A : 110 B : 99 Command> select * from dual where :a > 100 and :b < 100 and :c > 0; Enter Parameter 3 'C' (NUMBER) > 1 < X > 1 row found. Command>
You can set the default command-line options by exporting an environment variable called TTISQL. The value of the TTISQL environment variable is a string with the same syntax requirements as the TTISQL command line. If the same option is present in the TTISQL environment variable and the command line then the command line version always takes precedence.
Execute commands from ttIsql.inp.
ttIsql -f ttIsql.inp
Enable all output. Connect to DSN RunData and create the database if it does not exist.
ttIsql -v 4 -connStr "DSN=RunData;AutoCreate=1"
Print the interactive commands.
ttIsql -helpcmds
Print the full help text.
ttIsql -helpfull
Display the setting for all ttIsql set/show attributes:
Command> show all;
Connection independent attribute values:
autoprint = 0 (OFF)
columnlabels = 0 (OFF)
define = 0 (OFF)
echo 1 (ON)
FEEDBACK ON
multipleconnections =0 (OFF)
ncharencoding = LOCALE (US7ASCII)
prompt = 'COMMAND>'
timing = 0 (OFF)
verbosity = 2
vertrical = 0 (OFF)
Connection specific attribute values:
autocommit = 1 (ON)
Client timeout = 0
Connection String DSN=repdb1_1121;UID=timesten; DataStore=/DS/repdb1_1121;
DatabaseCharacterSet=AL32UTF8; ConnectionCharacterSet=US7ASCII;
DRIVER=/opt/TimesTen/tt1122/lib/libtten.so; PermSize=20;TempSize=20;TypeMode=1;
No errors.
isolation = READ_COMMITTED
Prefetch count = 5
Query threshold = 0 seconds (no threshold)
Query timeout = 0 seconds (no timeout)
serveroutput OFF
Current Optimizer Settings:
Scan: 1
Hash: 1
Range: 1
TmpHash: 1
TmpTable: 1
NestedLoop: 1
MergeJoin: 1
GenPlan: 0
TblLock: 1
RowLock: 1
Rowid: 1
FirstRow: 1
IndexedOr: 1
PassThrough: 0
BranchAndBound: 1
ForceCompile: 0
CrViewSemCheck: 1
ShowJoinOrder: 0
CrViewSemCheck: 1
UserBoyerMooreStringSearch: 0
DynamicLoadEnable: 1
DynamicLoadErrorMode: 0
NoRemRowIdOpt: 0
Current Join Order:
<>
Command
Prepare and execute an SQL statement.
ttIsql (c) 1996-2011, TimesTen, Inc. All rights reserved. ttIsql -connStr "DSN=RunData" Type ? or "help" for help, type "exit" to quit ttIsql. (Default setting AutoCommit=1) Command> prepare 1 SELECT * FROM my_table; Command> exec 1; Command> fetchall;
Example vertical command:
Command> call ttlogholds; < 0, 265352, Checkpoint , DS.ds0 > < 0, 265408, Checkpoint , DS.ds1 > 2 rows found. Command> vertical call ttlogholds; HOLDLFN: 0 HOLDLFO: 265352 TYPE: Checkpoint DESCRIPTION: DS.ds0 HOLDLFN: 0 HOLDLFO: 265408 TYPE: Checkpoint DESCRIPTION: DS.ds1 2 rows found. Command>
To create a new user, use single quotes around the password name for an internal user:
ttIsql -connStr "DSN=RunData" ttIsql (c) 1996-2000, TimesTen, Inc. All rights reserved. Type ? or "help" for help, type "exit" to quit ttIsql. (Default setting AutoCommit=1) Command> CREATE USER terry IDENDTIFIED BY `secret';
To delete the XLA bookmark mybookmark, use:
ttIsql -connStr "DSN=RunData" ttIsql (c) 1996-2000, TimesTen, Inc. All rights reserved. Type ? or "help" for help, type "exit" to quit ttIsql. (Default setting AutoCommit=1) Command> xlabookmarkdelete; XLA Bookmark: mybookmark Read Log File: 0 Read Offset: 268288 Purge Log File: 0 Purge Offset: 268288 PID: 2004 In Use: No 1 bookmark found. Command> xlabookmarkdelete mybookmark; Command> xlabookmarkdelete; 0 bookmarks found.
To run a SELECT query until the result "X" is returned or until the query times out at 10 seconds, use:
ttIsql -connStr "DSN=RunData" ttIsql (c) 1996-2000, TimesTen, Inc. All rights reserved. Type ? or "help" for help, type "exit" to quit ttIsql. (Default setting AutoCommit=1) Command> waitfor X 10 select * from dual; Command>
Example of managing XLA bookmarks
You can use the xlabookmarkdelete command to both check the status of the current XLA bookmarks and delete them. This command requires XLA privilege or object ownership.
For example, when running the XLA application, 'xlaSimple', you can check the bookmark status by entering:
Command> xlabookmarkdelete; XLA Bookmark: xlaSimple Read Log File: 0 Read Offset: 630000 Purge Log File: 0 Purge Offset: 629960 PID: 2808 In Use: No 1 bookmark found.
To delete the bookmark, enter:
Command> xlabookmarkdelete xlaSimple; Command>
Example parameters using "variable" and "print"
Substitution in ttIsql is modeled after substitution in SQL*Plus. To enable the substitution feature, use set define on or set define substitution_char'. The substitution character when the user specifies 'on' is '&'. It is disabled with 'set define off'.By default, substitution is off. The default is off because the & choice for substitution character conflicts with TimesTen's use of ampersand as the BIT AND operator.When enabled, the alphanumeric identifier following the substitution character is replace by the value assigned to that identifier. When disabled, the expansion is not performed.New definitions can be defined even when substitution is off. You can use the define command to list the definitions ttIsql predefines.
Command> show define define = 0 (OFF) Command> define DEFINE _PID = "9042" (CHAR) DEFINE _O_VERSION = "TimesTen Release 11.2.1.0.0" (CHAR) Command> select '&_O_VERSION' from dual; < &_O_VERSION > 1 row found. Command> set define on Command> SELECT '&_O_VERSION' FROM DUAL; < TimesTen Release 11.2.1.0.0 > 1 row found.
If the value is not defined, ttIsql prompts you for the value.When prompting with only one substitution character specified before the identifier, the identifier is defined only for the life of the one statement.If two substitution characters are used and the value is prompted, it acts as if you have explicitly defined the identifier.
Command> SELECT '&a' FROM DUAL; Enter value for a> hi < hi > 1 row found. Command> define a symbol a is UNDEFINED The command failed. Command> SELECT '&&a' FROM DUAL; Enter value for a> hi there < hi there > 1 row found. Command> define a DEFINE a = "hi there" (CHAR)
Additional definitions are created with the define command:
Command> define tblname = sys.dual Command> define tblname DEFINE tblname = "sys.dual" (CHAR) Command> select * from &tblname; < X > 1 row found.
Arguments to the run command are automatically defined to '&1', '&2', ... when you add them to the run or @ (and @@) commands:Given this script:
CREATE TABLE &1 ( a INT PRIMARY KEY, b CHAR(10) ); INSERT INTO &1 VALUES (1, '&2'); INSERT INTO &1 VALUES (2, '&3');SELECT * FROM &1;
Use the script:
Command> SET DEFINE ON Command> @POPULATE mytable Joe Bob; CREATE TABLE &1 ( a INT PRIMARY KEY, b CHAR(10) ); INSERT INTO &1 VALUES (1, '&2'); 1 row inserted. INSERT INTO &1 VALUES (2, '&3'); 1 row inserted. SELECT * FROM &1; < 1, Joe > < 2, Bob > 2 rows found. Command>
This example uses the variable command. It deletes an employee from the employee table. Declare empid and name as variables with the same data types as employee_id and last_name. Delete the row, returning employee_id and last_name into the variables. Verify that the correct row was deleted.
Command> VARIABLE empid NUMBER(6) NOT NULL;
Command> VARIABLE name VARCHAR2(25) INLINE NOT NULL;
Command> DELETE FROM employees WHERE last_name='Ernst'
> RETURNING employee_id, last_name INTO :empid,:name;
1 row deleted.
Command> PRINT empid name;
EMPID : 104
NAME : Ernst
The ttIsql utility supports only generic REF CURSOR variables, not specific REF CURSOR types.
Multiple ttIsql commands are allowed per line separated by semicolons.
The ttIsql utility command line accepts multiline PL/SQL statements, such as anonymous blocks, that are terminated with the "/" on it's own line. For example:
Command> set serveroutput on
Command> BEGIN
> dbms_ouput.put_line ('Hi There');
> END;
>/
Hi There
PL/SQL block successfully executed.
Command>
For UTF-8, NCHAR values are converted to UTF-8 encoding and then output.
For ASCII, those NCHAR values that correspond to ASCII characters are output as ASCII. For those NCHAR values outside of the ASCII range, the escaped Unicode format is used. For example:
U+3042 HIRAGANA LETTER A
is output as
Command> SELECT c1 FROM t1; < a\u3042 >
NCHAR parameters must be entered as ASCII N-quoted literals:
Command> prepare SELECT * FROM t1 WHERE c1 = ?; Command> exec;
Type '?;' for help on entering parameter values. Type '*;' to stop the parameter entry process.
Enter Parameter 1> N'XY';
On Windows, this utility is supported for all TimesTen Data Manager and Client DSNs.
Performs one of these operations:
Saves a migrate object from a TimesTen database into a binary data file.
Restores the migrate object from the binary data file into a TimesTen database.
Examines the contents of a binary data file created by this utility.
Migrated objects include:
Tables
Cache group definitions
Views and materialized views
Materialized view log definitions
Sequences
Replication schemes
Use the ttMigrate utility when upgrading major release versions of TimesTen, since database checkpoint and log files are not compatible between major releases. For an example, see the Oracle TimesTen In-Memory Database Installation Guide.
When you migrate a database into Release 11.2.1 from a previous release, TimesTen does not migrate users and user privileges. When you migrate a database between releases of Release 11.2.1 or into a release later than Release 11.2.1, TimesTen migrates users and user privileges.
Binary files produced by this utility are platform-dependent. For example a binary file produced on Windows must be restored on Windows. In client/server mode, use ttMigrateCS (UNIX only) utility to copy data between platforms.
Binary files produced by this utility are platform-specific. For example, a binary file produced on Windows 64-bit must be restored on Windows 64-bit. To copy data between platforms or bit levels, use ttMigrate with the ttMigrateCS client/server version (or Windows equivalent). On Windows systems, you can do the equivalent by using ttMigrate to connect to the source system from the target system through a defined TimesTen client DSN.
On UNIX, this utility is supported for TimesTen Data Manager DSNs. For TimesTen Client DSNs, use the utility ttMigrateCS.
This utility requires various privileges depending on the options specified. In general, a user must be the instance administrator or have the ADMIN privilege to use this utility.
Using the -r option requires the instance administrator privilege, as it generally creates a database. If the database has been created at the time this option is used, it requires CREATE ANY TABLE, CREATE ANY SEQUENCE, CREATE ANY VIEW, CREATE ANY MATERIALIZED VIEW, CREATE ANY CACHE GROUP, CREATE ANY INDEX privileges and ADMIN if autocreation of users is necessary. If the database is involved in replication or TimesTen Cache, then CACHE_MANAGER is also required.
Using the -c option to capture an entire database requires the ADMIN privilege. If the database is involved in replication or TimesTen Cache, then CACHE_MANAGER is also required. Using the -c option to capture a subset of the database objects (tables, views, materialized views, cache groups, sequences) requires SELECT ANY TABLE and SELECT ANY SEQUENCE privileges.
ttMigrate {-h | -help | -?}
ttMigrate {-V | -version}
To create or append a binary data file, use:
ttMigrate {-a | -c} [-v verbosity] [-nf] [-nr] [-fixNaN] [-saveAsCharset charset]
[-relaxedUpgrade | -exactUpgrade]
[-convertTypesToOra | -convertTypestoTT]]
[-activeDML | -noActiveDML]
{-connStr connection_string | DSN} data file [objectOwner.]objectName
To restore a database from a binary data file created by this utility, use:
ttmigrate -r [-C ckptFreq] [-v level] [-nf] [-nr] [-fixNaN] [-numThreads n] [-updateStats | -estimateStats percent] [-relaxedUpgrade | -exactUpgrade] [-inline rule] [-noCharsetConversion] [-cacheUid uid [-cachePwd pwd]] [-autorefreshPaused] [-convertTypesToOra | -convertTypesToTT] [-restorePublicPrivs] [-localhost host] [-delayFkeys | -noDelayFKeys] {DSN | -connstr connStr} dataFile [objectOwner.objectName...]
To list or display the contents of a binary data file created by this utility, use:
ttMigrate {-l | -L | -d | -D} dataFile [[objectowner.]name ...]
Note:
The append (-a) or create (-c) modes, the list (-l/-L) or describe (-d/-D) modes and the restore (-r) modes are exclusive of each other. You cannot specify any of these options on the same line as any other of these options.ttMigrate has the options:.
| Option | Description |
|---|---|
-a |
Selects append mode: Appends data to a pre-existing binary data file, that was originally created using ttMigrate -c. See "Create mode (-c) and Append mode (-a)" for more details. |
-activeDML |-noActiveDML |
Saves all tables in a foreign key hierarchy in a single transaction, maintaining consistency between these tables when there is active DML during the ttMigrate -c operation.
If
|
-c |
Create mode: Creates an original binary data file. See "Create mode (-c) and Append mode (-a)" for more details. |
-cacheUid |
The cache administration user ID to use when restoring asynchronous writethrough cache groups and cache groups with the AUTOREFRESH attribute. |
-cachePwd |
The cache administration password to use when restoring autorefresh and asynchronous writethrough cache groups and cache groups with the AUTOREFRESH attribute.
If the cache administration user ID is provided on the command line but the cache administration password is not, then |
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
-convertTypesToOra
|
Converts TimesTend Database data types to Oracle Database data types or Oracle Database data types to TimesTen data types. These options require the -relaxedUpgrade option.
In TimesTen 11.2.2 the default type mode is The These options apply to all table types except materialized views. Table types include: regular, cached, global and temporary tables. See also: |
-d |
Selects Describe mode. Displays a short description of the objects in the data file. See "Describe mode (-d)" for more details. |
-D |
Selects Long-describe mode. Displays a full description of the objects in the data file. See "Long-describe mode (-D)" for more details. |
dataFile |
The path name of the data file to which migrate objects are to be saved or from which migrate objects are to be restored. |
DSN |
Specifies an ODBC data source name of the database to be migrated. |
-estimateStats percent |
Specifies that ttMigrate should estimate statistics on restored tables and materialized views for the specified percentage of rows. Legal values for percentRows are 0 to 100, inclusive.
If you specify both Use of this flag may improve the performance of materialized view restoration and may also improve the performance of queries on the restored tables and views. |
-fixNaN |
Converts all NaN, Inf and -Inf values found in migrate objects to 0.0. This is useful for migrating data into releases of TimesTen that do not support the NaN, Inf and -Inf values. |
-h
|
Prints a usage message and exits. |
-inline rule |
Indicates the rule to be used for converting variable-length columns to INLINE in restore mode. The value for rule is one of:
If
|
-l |
Selects List mode. Lists the names of database objects in the specified data file. See "List mode (-l) and Long-list mode (-L)" for more details. |
-L |
Selects Long-list mode. Lists the names of database objects in the specified data file and other details about the database objects. See "List mode (-l) and Long-list mode (-L)" for more details. |
-r |
Selects Restore mode. Restores a database from a binary data file created by this utility. See "Restore mode (-r)" for more details. |
name |
The name of the database object(s) to be saved or restored. |
-nf |
Specifies that ttMigrate should not save or restore foreign key information when saving or restoring ordinary (non-cached) tables. |
-nr |
Specifies that ttMigrate should not save or restore table rows when saving or restoring ordinary (non-cached) tables. |
-noAutoCreateUsers |
Specifies that ttMigrate should not create users.
By default, TimesTen creates "disabled" users when migrating tables from releases earlier than 11.2.1. TimesTen creates users but does not assign any privileges to these users. You must explicitly assign privileges, including |
-relaxedUpgrade |
Save or restore the tables in a way that is compatible with a replication scheme that uses TABLE DEFINITION CHECKING RELAXED.Use of this option may cause the restored tables to be slightly more compact and slightly faster to access than otherwise.
This option should not be used in combination with a replication scheme that uses The default is |
-numThreads n |
Specifies the number of threads to use while restoring a database files. If unspecified, ttMigrate uses one thread to restore objects from the data file.
Valid values are 1 through 32. |
owner |
The owner of a migrate object. |
-exactUpgrade |
Save or restore the tables in a way that is compatible with a replication scheme that uses TABLE DEFINITION CHECKING EXACT. Use of this option may cause the restored tables to be slightly more compact and slightly faster to access than otherwise.
This option should not be used in combination with a replication scheme that uses This is the default. |
-saveAsCharset
|
Saves an object in the specified connection character set. ttMigrate returns an informational message if the connection character set is different from the database character set.
If this option is not set, by default, |
-updateStats |
Specifies that ttMigrate should update statistics on restored tables and materialized views.
If you specify both Use of this flag may improve the performance of materialized view restoration and may also improve the performance of queries on the restored tables and views. |
-v verbosity |
Specifies the verbosity level for messages printed when ttMigrate saves or restores a database. One of:
|
-V | -version |
Prints the release number of ttMigrate and exits. |
The following ttMigrate options are available in restore mode (-r) only:
| Option | Description |
|---|---|
-autorefreshPaused |
Restores cache groups with AUTOREFRESH attribute with autorefresh state paused. Otherwise the state is set to OFF. |
-C chkPtFreq |
Specifies that ttMigrate should checkpoint the database after restoring every chkPtFreq megabytes of data. A value of zero (the default) specifies that ttMigrate should never checkpoint the database. |
-convertCGTypes |
Determines the best type mapping from the underlying Oracle database tables to TimesTen cached tables using:
If this option is specified with either the |
-delayFkeys | -noDelayFkeys |
-delayFkeys - Delay creation of foreign keys until all tables have been restored. This can improve performance for parallel migration (ttMigrate -numThreads).
|
-localhost hostName |
Explicitly identifies the name or IP address of the local host when restoring replicated tables. |
-noCharsetConversion |
Restores data, retaining the connection character set that is stored in the data file. ttMigrate does not convert the connection character set to match the database character set.
If not set, See also: This option may be useful for legacy TimesTen users who may have migrated pre-11.2.2 data into a 11.2.2 or later release of TimesTen as |
-restorePublicPrivs |
Restores privileges that were granted to PUBLIC after the database was created. By default, the ttMigrate utility does not restore privileges granted to PUBLIC. You must explicitly specify this option to restore privileges to PUBLIC. |
Create mode (-c) and Append mode (-a)
In create mode, ttMigrate saves migrate objects from a TimesTen database into a new binary data file. If the data file does not exist, ttMigrate creates it. Otherwise, ttMigrate overwrites the existing file, destroying its contents.
The data file format used by ttMigrate is independent of any release of TimesTen, so it is possible to use ttMigrate to migrate data from one TimesTen release to another.
In Append mode, ttMigrate appends migrate objects from a TimesTen database to an existing data file. If the data file does not exist, ttMigrate creates it.
For each ordinary (non-cached) table, ttMigrate saves:
The table description: the name and type of each of the table's columns, including primary key and nullability information.
The table's index definitions: the name of each index and the columns contained in the index. The actual contents of the index are not saved; ttMigrate only saves the information needed to rebuild the index when the table is restored.
The table's foreign key definitions. You can disable the saving of foreign key definitions using the -nf option.
The rows of the table. You can disable the saving of rows using the -nr option.
For each cache group, ttMigrate saves the following:
The cache group definition: the cache group owner and name, the names of all tables in the cache group and any relevant cache group settings, such as the cache group duration.
Note:
AfterttMigrate has been used to restore a database, all autorefresh cache groups in the restored database have AUTOREFRESH state set to OFF, no matter how it was set on the source database. After restoring a cache group with ttMigrate -r, reset its AUTOREFRESH STATE to ON by using the ALTER CACHE GROUP statement (this can be done programmatically or with the ttIsql utility.All the cached tables in the cache group: the table name, column information, table attributes (propagate or read-only), WHERE clause, if any, foreign key definitions and index definitions.
For each view, ttMigrate saves the following:
All the same information as a normal table.
The query defining the view.
For each sequence, ttMigrate saves the following:
The complete definition of the sequence.
The sequence's current value.
For each user (except the instance administrator), ttMigrate saves the following:
User name.
The user's encrypted password.
Privileges that have been granted to the user.
For PUBLIC, ttMigrate saves all privileges that have been granted to PUBLIC after database creation.
If there are any replication schemes defined, ttMigrate saves all of the TTREP tables containing the replication schemes. Replication schemes should have names that are unique from all other database objects. It is not possible to migrate a replication scheme with the same name as any other database object.
Note:
ThettMigrate utility does not save the rows of a cached table into the data file, even if you have not specified the -nr option. The foreign key definitions of cached tables are always saved, regardless of the use of the -nf option, as they are needed to maintain the integrity of the cache group.By default, ttMigrate saves all database objects and users in the database to the data file, including tables, views, cache groups, sequences, users and replication schemes. Alternatively, you can give a list of database objects to be saved on the command line, except for replication schemes. The names in this list can contain the wildcard characters % (which matches one or more characters) and _ (which matches a single character). ttMigrate saves all database objects that match any of the given patterns. You do not need to be fully qualify names: If a name is given with no owner, ttMigrate saves all database objects that match the specified name or pattern, regardless of their owners.
You cannot save cached tables independently of their cache groups. If you list a cached table on the command line without also listing the corresponding cache group ttMigrate issues an error.
Use the -v option to control the information that ttMigrate prints while the save is in progress.
In Restore mode, ttMigrate restores all database objects from a data file into a TimesTen database.
For each ordinary (non-cached) table, ttMigrate restores:
The table, using the original owner, table name, column names, types and nullability and the original primary key.
The table's foreign keys. You can use the -nf flag to disable the restoration of foreign keys.
All indexes on the table.
All rows of the table. You can use the -nr flag to disable the restoration of rows.
For each cache group, ttMigrate restores:
The cache group definition, using the original cache group owner and name.
Each cached table in the cache group, using the original table names, column names, types and nullability, the original primary key, the table attributes (PROPAGATE or READONLY), and the WHERE clause, if any.
The foreign key definitions of the cached tables.
All the indexes on the cached tables.
Note:
ThettMigrate utility does not restore the rows of cached tables, even if you have not specified the -nr option. The foreign key definitions of the cached tables are always restored, regardless of the use of the -nf option, as they are needed to maintain the integrity of the cache group.By default, the -exactUpgrade option is set during restore.
By default, ttMigrate restores all tables and cache groups in the data file. Alternatively, you can list specific tables and cache groups to be restored on the command line. The names in this list must be fully qualified and cannot use wildcard characters.
You cannot restore cached tables independently of their cache groups. If you list a cached table on the command line without also listing the corresponding cache group, then ttMigrate issues an error.
Use the -v option to control the information that ttMigrate prints while the restoration is in progress.
The -inline option may be used to control whether variable length columns are restored as INLINE or NOT INLINE. See "Type specifications" in Oracle TimesTen In-Memory Database SQL Reference. In the default mode, -inlinepreserve, ttMigrate restores all variable-length columns with the same INLINE or NOT INLINE setting with which they were saved. In the other two modes, -inlinedsDefault and -inlinemaxlen, ttMigrate restores variable-length columns equal to or shorter than a threshold length as INLINE, and restores all other variable length columns as NOT INLINE. For-inlinedsDefault, this threshold is the default automatic INLINE length for a TimesTen database. The -inlinemaxlen mode restores variable length columns with a user-specified threshold length of maxlen as INLINE, and all other variable length columns as NOT INLINE, even if they were saved as INLINE. If maxlen is 0, then all variable-length columns are restored as NOT INLINE.
List mode (-l) and Long-list mode (-L)
In List mode, ttMigrate lists the names of database objects in the specified data file, including cached tables and the replication scheme TTREP tables.
In Long-list mode, ttMigrate lists the names of database objects in the data file, including cached tables and the replication scheme TTREP tables, along with the number of rows in each table and the index definitions for each table, the query defining each view and the specifications for each sequence.
By default, ttMigrate lists the replication scheme name and all the database objects in the file. Alternatively you can provide a list of names of database objects on the command line. The names in this list must be fully qualified and cannot use wildcard characters.
In Describe mode, ttMigrate gives a short description for database objects in the specified file.
For each table, ttMigrate lists the table name, the number of rows in the table, and the table's column definitions, primary key and foreign keys. For cached tables, ttMigrate also lists the table attributes (PROPAGATE or READONLY) and the table's WHERE clause, if any.
For views, ttMigrate also lists the query defining the view.
For cache groups, ttMigrate lists the cache group name, the number of tables in the cache group, the cache group duration and describes each cached table in the cache group.
For replication schemes, ttMigrate lists the replication scheme name and all the TTREP replication scheme tables in the same manner as user tables.
By default, ttMigrate describes all the database objects in the file. Alternatively, you can provide a list of names of database objects on the command line. The names in this list must be fully qualified and cannot use wildcard characters.
In Long-describe mode, ttMigrate gives a full description for database objects in the specified file.
For each table, ttMigrate lists the table's name and the number of rows in the table, the table's column definitions, primary key, foreign keys and index definitions. For cached tables, ttMigrate also lists the table attributes (PROPAGATE or READONLY) and the table's WHERE clause, if any.
For cache groups, ttMigrate lists the cache group name, the number of tables in the cache group, the cache group duration and describes each cached table in the cache group.
For sequences, ttMigrate lists all the values used to define the sequence and its current value.
For replication schemes, ttMigrate lists all the TTREP replication scheme tables in the same manner as user tables.
By default, ttMigrate describes all of database objects in the file. Alternatively, you can provide a list of names of database objects on the command line. The names in this list must be fully qualified and cannot use wildcard characters.
TimesTen to Oracle Database data type conversions
Both TimesTen and Oracle Database data types are supported in TimesTen 11.2.2 When migrating a database from an earlier version of TimesTen to TimesTen release 11.2.2, you can convert the data types in your database to the default Oracle type mode. This is not required, however.
In replication, the type mode must be the same on both sides of the replication scheme. Therefore you cannot convert the data types as part of an online upgrade, as TimesTen releases prior to 11.2.2 do not support Oracle Database data types.
Note:
If-convertTypesToOra is specified, and a DECIMAL (or NUMERIC) column exists in the database with a precision > 38, the column is converted to a NUMBER column with a precision of 38, and a warning is returned. If this occurs, and column values exist that overflow or underflow with a precision of 38, those values are reduced or increased to the maximum or minimum possible value for a NUMBER with a precision of 38. Because of this and some other cases, the data type conversion procedures (using -convertTypesToOra and -convertTypesToTT) are not guaranteed to be reversible. Converting types from TT->ORA->TT can result in columns and data which are different from the original in some cases.To convert from TimesTen data types to Oracle Database data types, use the -convertTypesToOra option.
The -convertTypesToOra option instructs ttMigrate to make the following type conversions as it saves or restores tables:
| From TimesTen Type | To Oracle Type |
|---|---|
TT_CHAR |
ORA_CHAR |
TT_VARCHAR |
ORA_VARCHAR2 |
TT_NCHAR |
ORA_NCHAR |
TT_NVARCHAR |
ORA_NVARCHAR2 |
TT_DECIMAL |
ORA_NUMBER |
TT_DATE |
ORA_DATE (append 12:00:00 am) |
TT_TIMESTAMP |
ORA_TIMESTAMP(6) |
Note:
Columns of typeTT_TINYINT, TT_SMALLINT, TT_INTEGER, TT_BIGINT, BINARY_FLOAT, BINARY_DECIMAL, TT_BINARY, TT_VARBINARY, and TT_TIME are not converted.For information on data types, see "Data Types" in the Oracle TimesTen In-Memory Database SQL Reference.
Oracle Database to TimesTen data type conversions
When migrating tables backward from TimesTen release 11.2.2 to an earlier version of TimesTen, you may need to convert Oracle Database data types to TimesTen data types, as the Oracle database data types were not supported in releases before 11.2.2.
To convert from Oracle Database data types to TimesTen data types, use the -convertTypesToTT option.
The -convertTypesToTT option instructs the ttMigrate utility to make the following type conversions as it saves or restores tables:
| From Oracle Type | To TimesTen Type |
|---|---|
ORA_CHAR |
TT_CHAR |
ORA_VARCHAR2 |
TT_VARCHAR |
ORA_NCHAR |
TT_NCHAR |
ORA_NVARCHAR2 |
TT_NVARCHAR |
ORA_NUMBER |
TT_DECIMAL |
ORA_DATE |
TT_DATE (time portion of date is silently truncated) |
ORA_TIMESTAMP |
TT_TIMESTAMP |
For information on data types, see "Data Types" in the Oracle TimesTen In-Memory Database SQL Reference.
Cache group data type conversions
When restoring a database that contains cache groups from a TimesTen release that is earlier than 7.0, use the -convertCGTypes. option to convert the data type of columns from pre-7.0 types to more clearly map with the data types of the columns in the Oracle database with which the cache group is associated.
The following table describes the type mapping.
| Pre-7.0 TimesTen Type | Oracle Type | Converted Type |
|---|---|---|
TINYINT |
NUMBER(p,s) when s > 0 |
NUMBER(p,s) |
TINYINT |
NUMBER(p,s) when s <= 0 |
TT_TINYINT |
SMALLINT |
NUMBER(p,s) when s > 0 |
NUMBER(p,s)
|
SMALLINT |
NUMBER(p,s) when s <= 0 |
TT_SMALLINT |
INTEGER |
NUMBER(p,s) when s > 0 |
NUMBER(p,s) |
INTEGER |
NUMBER(p,s) when s <= 0 |
TT_INTEGER |
BIGINT |
NUMBER(p,s) when s > 0 |
NUMBER(p,s) |
BIGINT |
NUMBER(p,s) when s <= 0 |
TT_BIGINT |
NUMERIC(p,s)DECIMAL(p,s) |
NUMBER |
NUMBER |
NUMERIC(p,s)DECIMAL(p,s) |
NUMBER(x,y) |
NUMBER(x,y) |
NUMERIC(p,s)DECIMAL(p,s) |
FLOAT(x) |
NUMBER(p,s) |
REAL |
Any | BINARY_FLOAT |
DOUBLE |
Any | BINARY_DOUBLE |
FLOAT(x) x <=24 |
Any | BINARY_FLOAT |
FLOAT(x) x >= 24 |
Any | BINARY_DOUBLE |
CHAR(x) |
Any | ORA_CHAR(x) |
VARCHAR(x) |
Any | ORAVARCHAR2(x) |
BINARY(x) |
Any | TT_BINARY(x) |
VARBINARY(x) |
Any | TT_VARBINARY(x) |
DATE |
DATE |
ORA_DATE |
TIMESTAMP |
DATE |
ORA_DATE |
TIME |
DATE |
ORA_DATE |
| Any1 | TIMESTAMP(m) |
ORA_TIMESTAMP(m) |
Note:
Any means the type value does not affect the converted result type.For information on data types, see "Data Types" in Oracle TimesTen In-Memory Database SQL Reference and "Mappings between Oracle Database and TimesTen data types" in Oracle TimesTen Application-Tier Database Cache User's Guide.
The ttMigrate utility restore (-r) and create (-c) commands return the following exit codes:
0 - All objects were successfully created or restored.
1 - Some objects successfully created or restored. Some objects could not be created or restored due to errors.
2 - Fatal error, for example, could not connect or could not open the data file.
3 - Ctrl-C or another signal received during the create or restore operation.
The following command dumps all database objects from database SalesDS into a file called sales.ttm. If sales.ttm exists, ttMigrate overwrites it.
ttMigrate -c SalesDS sales.ttm
This command appends all database objects in the SalesDS database owned by user MARY to sales.ttm:
ttMigrate -a SalesDS sales.ttm MARY.%
This command restores all database objects from sales.ttm into the SalesDS database:
ttMigrate -r SalesDS sales.ttm
This command restores MARY.PENDING and MARY.COMPLETED from sales.ttm into SalesDS (migrate objects are case-insensitive):
ttMigrate -r SalesDS sales.ttm MARY.PENDINGMARY.COMPLETED
This command lists all migrate objects saved in sales.ttm:
ttMigrate -l sales.ttm
When migrating backward into a release of the Oracle TimesTen In-Memory Database that does not support features in the current release, TimesTen generally issues a warning and continues without migrating the unsupported features. In a few cases, where objects have undergone conversion, ttMigrate may fail and return an error message. This may be the case with conversions of data types, character sets and primary key representation.
The following restrictions, limitations and suggestions should be considered before preparing to use ttMigrate.
Asynchronous materialized view: When migrating to a previous release, asynchronous materialized views are ignored and TimesTen returns a warning.
Cache groups: In restore mode, the presence of foreign key dependencies between tables may require ttMigrate to reorder tables to ensure that a child table is not restored before a parent table.
When migrating databases that contain cache groups from a previous release of TimesTen to TimesTen 7.0 or greater, you must use the option -convertTypesToOra. See "Cache group data type conversions" for a description of the data type mapping.
Character columns in cached tables must have not only the same length but also the same byte semantics as the underlying Oracle database tables. Cache group migration fails when there is a mismatch in the length or length semantics of any of its cached tables.
The connection attribute PassThrough with a nonzero value is not supported with this utility and returns an error.
Character sets: By default, ttMigrate stores table data in the database character set, unless you have specified the -saveAsCharset option. At restore time, conversion to another character set can be achieved by migrating the table into a database that has a different database character set. When migrating data from a release of TimesTen that is earlier than 7.0, TimesTen assumes that the data is in the target database's character set. If the data is not in the same database character set as the target database, the data may not be restored correctly.
When migrating columns with BYTE length semantics between two databases that both support NLS but with different database character sets, it is possible for migration to fail if the columns in the new database are not large enough to hold the values in the migrate file. This could happen, for example, if the source database uses a character set whose maximum byte-length is 4 and the destination database uses a character set whose maximum byte-length is 2.
TimesTen issues a warning whenever character set conversion takes place to alert you to the possibility of data loss due to conversion.
Data type conversions: When migrating data from a pre-7.0 release of TimesTen, you must explicitly request data type conversions, using either the -convertTypesToOra or the -convertTypesToTT options.
ttMigrate saves the length semantic annotation (BYTE or CHAR) of CHAR and VARCHAR columns and restores these annotations when restoring into TimesTen releases that support them. When migrating backward into a TimesTen release that does not support these annotations, columns with CHAR length semantics are converted to BYTE length, but their lengths are adjusted to match the byte length of the original columns. When migrating forward from a release that does not support these annotations, BYTE length semantics are used.
Foreign key dependencies: In restore mode, the presence of foreign key dependencies between tables may require ttMigrate to reorder tables to ensure that a child table is not restored before any of its parents. Such dependencies can also prevent a child table from being restored if any of its parent tables were not restored. For example, when restoring a table A that has a foreign key dependency on a table B, ttMigrate first checks to verify that table B exists in the database. If table B is not found, ttMigrate delays the restoration of table A until table B is restored. If table B is not restored as part of the ttMigrate session, TimesTen prints an error message indicating that table A could not be restored due to an unresolved dependency.
Indexes: TimesTen supports range indexes as primary-key indexes into TimesTen releases that support this feature. When migrating backward into a release that does not support range indexes as primary-key indexes, the primary keys are restored as hash indexes of the default size. When migrating forward from a release that does not support range indexes as primary-key indexes, the primary keys are restored as hash indexes of the same size as the original index.
TimesTen also supports bitmap indexes. When migrating backward into a release that does not support bitmap indexes, ttMigrate converts the bitmap indexes to range indexes.
INLINE columns: When migrating TimesTen tables that contain INLINE variable length columns to a release of TimesTen that is earlier than 5.1, you must explicitly use the -relaxedUpgrade option. Using the default -exactUpgrade option results in an error. The INLINE column attributes are maintained, unless you specify otherwise using the -inline option.
Materialized view logs: TimesTen does not save the content of materialized view logs, only the definition.
Replication: Before attempting a full store migrate of replicated stores, ensure the host name and database name are the same for both the source and destination databases.
System views: TimesTen does not save the definitions or content of system vies during migration.
Other considerations: Because ttMigrate uses a binary format, you cannot use ttMigrate to:
Migrate databases between hardware platforms.
Restore data saved with ttBackup or use ttBackup to restore data saved with ttMigrate.
Platforms: You can use ttMigrate together with ttMigrateCS (client server version of ttMigrate) to migrate databases between 32- and 64-bit platforms or bit levels. You must use the -relaxedUpgrade option when restoring data on a new bit-level. In the case of changing bit-levels, the database cannot be involved in a replication scheme. Follow the examples in "Moving a database between 32-bit and 64-bit platforms" in the Oracle TimesTen In-Memory Database Installation Guide.
On Windows, you can use ttMigrate to access databases from any release of TimesTen. On Windows, this utility is supported for all TimesTen Data Manager and Client DSNs.
On UNIX, the release of ttMigrate must match the release of the database you are connecting to.
It is recommended that you do not run DDL SQL commands while running ttMigrate to avoid lock contention issues for your application.
ttmodinstall {-h | -help | -?}
ttmodinstall {-V | -version}
ttmodinstall -port portNumber
ttmodinstall -tns_admin path
ttmodinstall -enablePLSQL
ttmodinstall -crs
ttmodinstall has the options:
| Option | Description |
|---|---|
-h
|
Displays help information. |
-crs |
Create or modify Oracle Clusterware configuration.
For more information, see "Using Oracle Clusterware to Manage Active Standby Pairs" in Oracle TimesTen In-Memory Database Replication Guide. |
-enablePLSQL |
Enables PL/SQL in the database. |
-port portNumber |
Changes the daemon port for the current instance of TimesTen to portNumber. This is useful if you discover that other processes are listening on the port that you assigned to TimesTen at installation time.
You can use this option to assign the port for the TimesTen cluster agent. See "Using Oracle Clusterware to Manage Active Standby Pairs" in Oracle TimesTen In-Memory Database Replication Guide. |
-tns_admin path |
Sets the value for the TNS_ADMIN environment variable. Specify the directory where the tnsnames.ora file can be found. |
-V | -version |
Display TimesTen version information. |
Displays existing replication definitions and monitors replication status. The ttRepAdmin utility is also used when upgrading to a new release of TimesTen, as described in Oracle TimesTen In-Memory Database Installation Guide.
ttRepAdmin {-h | -help | -?}
ttRepadmin {-V | -version}
ttRepAdmin -self -list [-scheme [owner.]schemeName]
{DSN | -connStr connectionString}
ttRepAdmin -receiver [-name receiverName]
[-host receiverHostName] [-state receiverState] [-reset]
[-list] [-scheme [owner.]schemeName]
{DSN | -connStr connectionString}
ttRepAdmin -log {DSN | -connStr connectionString}
ttRepAdmin -showstatus {-awtmoninfo} {DSN | -connStr connectionString}
ttRepAdmin -showconfig {DSN | -connStr connectionString}
ttRepAdmin -bookmark {DSN | -connStr connectionString}
ttRepAdmin -wait [-name receiverName] [-host receiverHostName]
[-timeout seconds] {DSN | -connStr connectionString}
ttRepAdmin -duplicate -from srcDataStoreName
-host srcDataStoreHost
[-localIP localIPAddress] [-remoteIP remoteIPAddress]
[-setMasterRepStart] [-ramLoad] [-delXla]
[-UID userId] [-PWD pwd | -PWDCrypt encryptedPwd]
[-drop { [owner.]table ... | [owner.]sequence |ALL }]
[-truncate { [owner.]table ... | ALL }]
[-compression 0 | 1] [-bandwidthmax maxKbytesPerSec]
[-initCacheDr [-noDRTruncate][-nThreads]]
[-keepCG [-cacheUid cacheUid [-cachePwd cachePwd]]
[-recoveringNode | -deferCacheUpdate]
| -nokeepCG]
[-remoteDaemonPort portNo] [-verbosity {0|1|2}]
[-localhost localHostName]
{destDSN | -connStr connectionString}
Use the ttRepAdmin utility for many replication operations. These operations fall into the following categories:
Use this form of ttRepAdmin to obtain help and the current version of TimesTen.
ttRepAdmin {-h | -help | -?}
ttRepadmin {-V | -version}
| Option | Description |
|---|---|
-h
|
Display help information. |
-V | -version |
Display TimesTen version information. |
Use this form of ttRepAdmin to obtain summary information about a database.
ttRepAdmin -self -list [-scheme [owner.]schemeName] {DSN | -connStr connectionString}
ttRepAdmin -self -list has the options:
| Option | Description |
|---|---|
DSN |
Data source name of a master or subscriber database. |
-connStr connection_string |
Connection string of a master or subscriber database. |
-self |
Specified database. |
-list |
Lists database name, host, port number, and bookmark position. |
-scheme [owner.]schemeName] |
Name of replication scheme when there is more than one scheme. |
Use this form of ttRepAdmin to check the status or reset the state of a subscriber (receiver) database.
ttRepAdmin -receiver [-name receiverName] [-host receiverHostName] [-state receiverState] [-reset] [-list] [-scheme [owner.]schemeName] {DSN | -connStr connectionString}
ttRepAdmin -receiver has the options:
| Option | Description |
|---|---|
DSN |
Data source name of the master database. |
-connStr connection_string |
Connection string of the master database. |
-receiver |
Subscriber databases receiving updates from the master. Use -name and -host to specify a specific subscriber database. |
-name receiverName |
A specific subscriber (receiving) database. The receiverName is the last component in the database path name. |
-host receiverHostName |
Host name or TCP/IP address of the subscriber host. |
-state start
|
Sets the state of replication for the subscriber.
See "Setting the replication state of subscribers" in Oracle TimesTen In-Memory Database Replication Guide for more information. |
-reset |
Clears the bookmark in the master database log for the latest transaction to be sent to a given subscriber. This option should only be used when the transaction numbering of the master database is changed, such as when the database is re-created using ttMigrate or ttBackup. If the master database is saved and restored using ttBackup and ttRestore, transaction numbering is preserved and this option should not be used. |
-list |
Lists information about a replication definition. |
-scheme [owner.]schemeName] |
Specifies the replication scheme name when there is more than one scheme. |
ttRepAdmin -receiver -list my_dsn
The above syntax lists replication information for all the subscribers of the master database, my_dsn.
ttRepAdmin -receiver -name rep_dsn -list my_dsn
The above syntax lists replication information for the rep_dsn subscriber of the master database, my_dsn.
ttRepAdmin -receiver -name rep_dsn -reset my_dsn
The above syntax resets the replication bookmark with respect to the rep_dsn subscriber of the master database. Should only be used when migrating a replicated database with ttMigrate or ttBulkCp.
ttRepAdmin -receiver -name rep_dsn -state Start my_dsn
The above syntax resets the replication state of the rep_dsn subscriber database to the Start state with respect to the master database, my_dsn.
Use this form of ttRepAdmin to create a new database with the same contents as the master database.
The following must be true for you to perform the ttRepAdmin -duplicate:
Only the instance administrator can run ttRepAdmin -duplicate.
The instance administrator must have the same operating system username on both source and target computer to execute ttRepAdmin -duplicate.
You must provide the user name and password with the -UID and -PWD options for an internal user with the ADMIN privilege on the source database.
You must run ttRepAdmin on the target host.
The DSN specified must be a direct-mode DSN, not a server DSN.
Before running the ttRepAdmin -duplicate command, use ttStatus to ensure the replication agent is started for the source database.
ttRepAdmin -duplicate -from srcDataStoreName -host srcDataStoreHost [-localIP localIPAddress] [-remoteIP remoteIPAddress] [-setMasterRepStart] [-ramLoad] [-delXla] -UID userId (-PWD pwd | -PWDCrypt encryptedPwd) [-drop { [owner.]table ... | [owner.]sequence |ALL }] [-truncate { [owner.]table ... | ALL }] [-compression 0 | 1] [-bandwidthmax maxKbytesPerSec] [-initCacheDr [-noDRTruncate] [-nThreads]] [-keepCG [-cacheUid cacheUid [-cachePwd cachePwd]] [-recoveringNode | -deferCacheUpdate] |-nokeepCG] [-remoteDaemonPort portNo] [-verbosity {0|1|2}] [-localhost localHostName] {destDSN | -connStr connectionString}
ttRepAdmin -duplicate has the options:
| Option | Description |
|---|---|
-bandwidthmax maxKbytesPerSec |
Specifies that the duplicate operation should not put more than maxKbytesPerSec KB of data per second onto the network. A value of 0 indicates that there should be no bandwidth limitation. The default is 0. The maximum is 9999999. |
-compression 0 | 1 |
Enables or disables compression during the duplicate operation. The default is 0 (disabled). |
-connStr connection_string |
Specifies the connection string of the destination database. |
-delXla |
Removes all the XLA bookmarks as part of the duplicate operation. Use this option if you do not want to copy the bookmarks to the duplicate database. |
destDSN |
Indicates the data source name of the destination database. |
-drop {[owner.]table ... |[owner.]sequence |ALL |
Drops any tables or sequences that are copied as part of the -duplicate operation but which are not included in the replication scheme. ttRepAdmin ignores the option if the table is a cache group table. |
-duplicate |
Creates a duplicate of the specified database using replication to transmit the database contents across the network. See "Duplicating a database" in Oracle TimesTen In-Memory Database Replication Guide. |
-from srcDataStoreName |
Used with -duplicate to specify the name of the sender (or master) database. The srcDataStoreName is the last component in the database path name. |
-host srcDataStoreHost |
Defines the host name or TCP/IP address of the sender (or master) database. |
-initCacheDr |
Initializes disaster recovery. Must be used with -cacheUid and -cachePwd options. |
-keepCG [-cacheUid cacheUid -cachePwd cachePwd] [-recoveringNode | -deferCacheUpdate] | -noKeepCG |
-keepCG and -noKeepCG specify whether tables in cache groups should be maintained as cache group tables or converted to regular tables in the target database. The default is -noKeepCG.
If no password is provided, If you cannot connect to the Oracle database or the Oracle database is down, then specify the |
-localhost hostName |
Use with -duplicate and -setMasterRepStart to explicitly identify the name or IP address of the local host. |
-localIP localIPAddress |
Specifies the alias or IP (IPv4 or IPv6) address of the local network interface to be used. If not specified, ttRepAdmin chooses any compatible interface. |
-noDRTruncate |
Used with the -initCacheDr option, -noDRTruncate disables truncation of Oracle tables during the initial rollout process for the remote subscriber on the Disaster Recovery site. When –noDRTruncate is specified, TimesTen does not truncate the Oracle Database tables that correspond to the Asynchronous Writethrough cache group tables in an active standby pair replication scheme. |
-nThreads n |
Used with the -initCacheDr option, -nThreads indicates the number of threads used to truncate the Oracle database tables and push the data in the cache into Oracle during the initialization process. |
-PWD pwd |
The password of the internal user specified in the -UID option. |
-PWDCrypt encryptedPwd |
The encrypted password of the user specified in the -UID option. |
-ramLoad |
Keeps the database in memory upon completion of the duplicate operation. This option avoids the unload/reload database cycle to improve the performance of the duplicate operation when copying large databases. After the duplicate option, RAM Policy for the database is set to manual. Use the ttAdmin utility to make further changes to the RAM policy. |
-remoteDaemonPort portNo |
The port number of the remote main daemon.
The port number supplied as an argument to this option is used unless the value is zero. In that case the default behavior to determine the port number is used. The |
-remoteIP remoteIPAddress |
Specifies the alias or IP (IPv4 or IPv6) address of the remote or destination network interface to be used. If not specified, ttRepAdmin chooses any compatible interface. |
-setMasterRepStart |
When used with -duplicate, this option sets the replication state for the newly created database to the Start state just before the database is copied across the network. This ensures that all updates made to the source database after the duplicate operation are replicated to the newly duplicated local database. Any unnecessary transaction log files for the database are removed. |
-truncate [owner.]table ...| ALL |
Truncates any tables that are copied as part of the -duplicate operation but which are not included in the replication scheme. ttRepAdmin ignores the option if the table is a cache group table. |
-UID userid |
The user ID of a user having the ADMIN privilege on the source database must be supplied. This must be an internal user. |
-verbosity {0 | 1 | 2} |
Provide details of the communication steps within the duplicate process and reports progress information about the duplicate transfer.
|
Example 3-1 Duplicating a database
On the source database, create a user and grant the ADMIN privilege to the user:
CREATE USER ttuser IDENTIFIED BY ttuser; User created. GRANT admin TO ttuser;
The instance administrator must have the same user name on both instances involved in the duplication. Logged in as the instance administrator, duplicate the ds1 database on server1 to the ds2 database:
ttRepAdmin -duplicate -from ds1 -host "server1"
-UID ttuser -PWD ttuser
-connStr "dsn=ds2;UID=ttuser;PWD=ttuser"
Example 3-2 Duplicating a database with cache groups
Use the -keepCG option to keep cache group tables when you duplicate a database. Specify the cache administration user ID and password with the -cacheuid and -cachepwd options. If you do not provide the cache administration user password, ttRepAdmin prompts for a password.
If the cache administration user ID is orauser and the password is orapwd, duplicate database dsn1 on host1:
ttRepAdmin -duplicate -from dsn1 -host host1 -uid ttuser -pwd ttuser
-keepCG -cacheuid orauser -cacheuid orapwd "DSN=dsn2;UID=;PWD="
The UID and PWD for dsn2 are specified as null values in the connection string so that the connection is made as the current operating system user, which is the instance administrator. Only the instance administrator can run ttRepAdmin -duplicate. If dsn2 is configured with PWDCrypt instead of PWD, then the connection string should be "DSN=dsn2;UID=;PWDCrypt=".
Example 3-3 Setting the replication state on the source database
The -setMasterRepStart option causes the replication state in the srcDataStoreName database to be set to the Start state before it is copied across the network and then keeps the database in memory. It ensures that any updates made to the master after the duplicate operation has started are copied to the subscriber.
You can use the -localhost option to identify the local host by host name or IP address. These options ensure that all updates made after the duplicate operation are replicated from the remote database to the newly created or restored local database.
ttRepAdmin -duplicate -from srcDataStoreName -host srcDataStoreHost -setMasterRepStart -ramLoad -UID timesten_user -PWD timesten_user] -localhost localHostName [destDSN | -connStr connectionString ]
Use this form of ttRepAdmin to assure that all the updates in the log are replicated to all subscribers before call returns.
ttRepAdmin -wait [-name receiverName] [-host receiverHostName] [-timeout seconds] {DSN | -connStr connectionString}
ttRepAdmin -wait has the options:
| Option | Description |
|---|---|
DSN |
Indicates the data source name of the master database. |
-connStr connection_string |
Specifies the connection string of the master database. |
-wait |
Waits for replication to become current before continuing. |
-name receiverName |
Identifies the database. The database name is the last component in the database path name. |
-host receiverHostName |
Defines the host name or TCP/IP address of the subscriber host. |
-timeout seconds |
Specifies timeout value in seconds. ttRepAdmin returns within this amount of time, even if all updates to subscribers have not been completed. |
ttRepAdmin -wait -name receiverName -host receiverHostName -timeout seconds -dsn DSN
The above syntax provides a way to ensure that all updates, committed at the time this program was invoked, have been transmitted to the subscriber, receiverName, and the subscriber has acknowledged that all those updates have been durably committed at the subscriber database. The timeout in seconds limits the wait.
Note:
IfttRepAdmin -wait is invoked after all write transaction activity is quiesced at a store (there are no active transactions and no transactions have started), it may take 60 seconds or more before the subscriber sends the acknowledgment that all updates have been durably committed at the subscriber.
ttRepAdmin -wait -dsn DSN
In the above syntax, if no timeout and no subscriber name are specified, ttRepAdmin does not return until all updates committed at the time this program was invoked have been transmitted to all subscribers and all subscribers have acknowledged that all those updates have been durably committed at the subscriber database.
Use this form of ttRepAdmin to check the size of the transaction log files, bookmark position, or replication configuration of a master database.
ttRepAdmin -log {DSN | -connStr connectionString}
ttRepAdmin -showstatus {-awtmoninfo} {DSN | -connStr connectionString}
ttRepAdmin -showconfig {DSN | -connStr connectionString}
ttRepAdmin -bookmark {DSN | -connStr connectionString}
The ttRepAdmin monitor operations have the options:
| Option | Description |
|---|---|
DSN |
Indicates the data source name of the master database. |
-awtmoninfo |
If you have enabled monitoring for AWT cache groups by calling the AwtMonitorConfig procedure, you can display the monitoring results by using the this option.
If AWT monitoring is enabled,
|
-connStr connection_string |
Specifies the connection string of the master database. |
-log |
Prints out number and size of transaction log files retained by replication to transmit updates to other databases. |
-showconfig |
Lists the entire replication configuration.
See "Show the configuration of replicated databases" in Oracle TimesTen In-Memory Database Replication Guide for more information. |
-showstatus |
Reports the current status of the specified replicated database.
See "Use ttRepAdmin to show replication status" in Oracle TimesTen In-Memory Database Replication Guide for more information. |
-bookmark |
Reports the latest marker record from where replication must read the log, the most recently created log sequence number, and the latest log sequence number whose record has been flushed to disk.
Bookmarks are not supported if you have configured parallel replication. See "Show replicated log records" in Oracle TimesTen In-Memory Database Replication Guide for more information. |
If AWT monitoring is enabled, this utility displays the following information in addition to other ttRepAdmin -showstatus output.
TimesTen processing time: The total number of milliseconds spent in processing AWT transaction data since monitoring was enabled.
Oracle bookmark management time: The total number of milliseconds spent in managing AWT metadata on Oracle since monitoring was enabled.
Oracle execute time: The total number of milliseconds spent in OCI preparation, binding and execution for AWT SQL operations since monitoring was enabled. This statistic includes network latency between TimesTen and the Oracle database.
Oracle commit time: The total number of milliseconds spent in committing AWT updates on Oracle since monitoring was enabled. This statistic includes network latency between TimesTen and the Oracle database.
Time since monitoring was started.
Total number of TimesTen row operations: The total number of rows updated in AWT cache groups since monitoring was enabled.
Total number of TimesTen transactions: The total number of transactions in AWT cache groups since monitoring was enabled.
Total number of flushes to Oracle: The total number of times that TimesTen data has been sent to the Oracle database.
The output also includes the percentage of time spent on TimesTen processing, Oracle bookmark management, Oracle execution and Oracle commits.
ttRepAdmin -log DSN
The above syntax reports the number of transaction log files that replication is retaining to transmit updates to other databases. The replication agent retains a transaction log file until all updates in that transaction log file have been successfully transferred to each subscriber database.
ttRepAdmin -showconfig DSN
The above syntax reports the entire replication configuration. It lists all the subscribers for the specified DSN, the names and details of the tables being replicated, and all the subscriptions.
ttRepAdmin -showstatus DSN
The above syntax reports the current state of the database for the specified DSN. The output includes the state of all the threads in the replication agents for the replicated databases, bookmark locations, port numbers, and communication protocols.
ttRepAdmin -bookmark DSN
The above syntax prints out the log sequence numbers of the earliest log record still needed by replication, the last log record written to disk, and the last log record generated.
ttRepAdmin -showstatus -awtmoninfo myDSN
[other -showstatus output]
...
AWT Monitoring statistics
--------------------------
TimesTen processing time : 0.689000 millisecs (0.164307 %)
Oracle bookmark management time : 3.229000 millisecs (0.770027%)
Oracle execute time : 342.908000 millisecs (81.774043 %)
Oracle commit time : 72.450000 millisecs (17.277315 %)
Time since monitoring was started: 8528.641000 millisecs
Cache-connect Operational Stats :
Total Number of TimesTen row operations : 2
Total Number of TimesTen transactions : 2
Total Number of flushes to Oracle : 2
The above syntax and output shows the AWT monitoring status.
The ttRepAdmin utility is supported only for TimesTen Data Manager DSNs. It is not supported for TimesTen Client DSNs.
You must use the -scheme option when specifying more than one replication scheme, or when more than one scheme exists involving the specified database.
Using SQL configuration, you can create multiple replication schemes in the same database. If there is only one replication scheme, the ttRepAdmin utility automatically determines the scheme. If there is more than one scheme, you must use the ttRepAdmin -scheme option to specify which scheme to use.
When configuring replication for databases with the same name on different hosts, you can indicate which database you want to operate on by using -host. For example, if all the subscribers have the name DATA, you can set the replication state on host SW1 with:
ttRepAdmin -receiver -name DATA -host SW1 -state start DSN
Creates a database from a backup that has been created using the ttBackup utility. If the database exists, ttRestore does not overwrite it.
The attributes in the ttRestore connection string can contain any of the first connection or general connection attributes. It can also include the data store attribute LogDir. All other data store attributes are copied from the backup files. The LogDir attribute enables the restored database to be relocated.
The ttRestore action is somewhat more powerful than a first connect, as it can move the database. It is somewhat less powerful than creating a new database, as it cannot override the data store attributes, except for the LogDir attribute.
For an overview of the TimesTen backup and restore facility, see "Migration, Backup, and Restoration" in the Oracle TimesTen In-Memory Database Installation Guide.
ttRestore {-h | -help | -?}
ttRestore {-V | -version}
ttRestore [-fname filePrefix] [-noconn] -dir directory
{DSN | -connStr connectionString}
ttRestore -i [-noconn] {DSN | -connStr connection_String}
ttRestore has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies an ODBC data source name of the database to be administered. |
-dir directory |
Specifies the directory where the backup files are stored. |
-fname filePrefix |
Specifies the file prefix for the backup files in the backup directory. The backup files must have been stored in the backup directory with this prefix.
The default value for this parameter is the file name portion of the |
-h
|
Prints a usage message and exits. |
-i |
Read standard input for the backup data. You cannot use the -dir or -fname options with -i. |
-noconn |
To ensure that the restore was successful, ttRestore connects to the database as a last step. This option disables that last connect. We recommend that you specify this option for best performance. If this option is not specified, the database is loaded into memory and unloaded from memory. |
-V | -version |
Prints the release number of ttRestore and exits. |
ttRestore -dir /users/pat/TimesTen/backups -fname FastInsBkup FastIns
To back up a database named origDSN to the directory /users/rob/tmp and restore it to database named restoredDSN, use:
ttBackup -dir /users/rob/tmp -fname restored origDSN ttRestore -dir /users/rob/tmp -fname restored restoredDSN
The value of fname is the name that you want for the prefix portion of the backup file name.
On UNIX, to restore a tape backup to the FastIns database, use:
dd bs=64k if=/dev/rmt0 | ttRestore -i FastIns
The ttBackup utility and the ttRestore utility backup and restore databases only when the first three numbers of the TimesTen release and the platform are the same. For example, you can backup and restore files between releases 11.2.2.2.0 and 11.2.2.3.0. You cannot backup and restore files between releases 11.2.1.9.0 and 11.2.2.3.0. You can use the ttBulkcp or ttMigrateCS (UNIX only) utility to migrate databases across major releases or operating systems. You can use ttMigrate together with ttMigrateCS (client server version of ttMigrate) to migrate databases between 32- and 64-bit platforms or bit levels. You must use the -relaxedUpgrade option when restoring data on a new bit-level. In the case of changing bit-levels, the database cannot be involved in a replication scheme. Follow the examples in "Moving a database between 32-bit and 64-bit platforms" in the Oracle TimesTen In-Memory Database Installation Guide.
You can backup databases containing cache groups with the ttBackup utility. However, when restoring such a backup, special consideration is required as the restored data within the cache groups may be out of date or out of sync with the data in the back end Oracle database. See the section on "Backing up and restoring a database with cache groups" in the Oracle TimesTen Application-Tier Database Cache User's Guide for details.
Prints out the schema, or selected objects, of a database. The utility can list the following schema objects that are found in SQL CREATE statements:
Tables
Indexes
Cache group definitions
Sequences
Views
Materialized view logs
Column definitions, including partition information
PL/SQL program units
The level of detail in the listing and the objects listed are controlled by options. The output represents a point in time snapshot of the state of a database rather than a history of how the database came to arrive at its current state, perhaps through ALTER statements. An entire database, including data, cannot be completely reconstructed from the output of ttSchema. The ttIsql utility can play back the output of ttSchema utility to rebuild the full schema of a database.
On UNIX, this utility is supported for TimesTen Data Manager DSNs. For TimesTen Client DSNs, use the utility ttSchemaCS.
This utility requires no privileges beyond those needed to perform describe operations on database objects.
This utility prints information only about the objects owned by the user executing the utility, and those objects for which the owner has SELECT privileges. If the owner executing the utility has ADMIN privilege, ttSchema prints information about all objects.
ttSchema {-h | -help | -?}
ttSchema {-V | -version}
ttSchema [-l] [-c] [-fixedTypes] [-st | -systemTables]
[ -list {all | tables | views | sequences |
cachegroups | repschemes |synonyms | plsql} [,...] ]
[-plsqlAttrs | -noplsqlAttrs]
[-plsqlCreate |-[no]plsqlCreateOrReplace]
{-connStr connection_string | DSN }
[[owner.]object_name][...]
ttSchema has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
-c |
Compatibility mode. Limits the use of TimesTen-specific and release-specific keywords and extensions. This may be useful if the ttSchema output is being used as input to an older TimesTen release, or to some other database system, such as the Oracle database.
The |
DSN |
Specifies an ODBC data source name of the database from which to get a schema. |
-fixedTypes |
Uses fully qualified data type names regardless of the current TypeMode value. |
-h
|
Prints a usage message and exits. |
-l |
One per-line listing of objects in the database. |
-list {all | tables | views | sequences | cachegroups | repschemes |synonyms | plsql}[,...] |
A comma-delimited (no space after comma) list of objects to generate. Lists only those types of objects specified. Default is -list all.
|
[owner.]object_name |
Limits the scope of the output to specified database object(s). |
-plsqlAttrs |-noplsqlAttrs |
Controls whether ttSchema emits ALTER SESSION statements with CREATE statements for PL/SQL program units.
If If |
-plsqlCreate | -[no]plsqlCreateOrReplace |
If -plsqlCreate is specified, ttSchema emits CREATE PROCEDURE, CREATE PACKAGE or CREATE FUNCTION statements for PL/SQL program units.
If |
-st | -systemTables |
Include system tables. System tables are omitted by default. |
-V | -version |
Prints the release number of ttSchema and exits. |
Objects in the orderdsn database are created with these SQL statements:
CREATE TABLE ttuser.customer (
cust_num INTEGER NOT NULL PRIMARY KEY,
region CHAR(2) NOT NULL,
name VARCHAR2(80),
address VARCHAR2(255) NOT NULL);
CREATE SEQUENCE ttuser.custid MINVALUE 1 MAXVALUE 1000000;
CREATE TABLE ttuser.orders (
ord_num INTEGER NOT NULL PRIMARY KEY,
cust_num INTEGER NOT NULL,
when_placed TIMESTAMP NOT NULL,
when_shipped TIMESTAMP,
FOREIGN KEY(cust_num) REFERENCES ttuser.customer (cust_num));
CREATE MATERIALIZED VIEW ttuser.order_summary AS
SELECT cust.name, ord.ord_num, count(*) ord_count
FROM ttuser.orders ord, ttuser.customer cust
WHERE ord.cust_num = cust.cust_num
GROUP BY cust.name, ord.ord_num;
Example 3-4 ttSchema for the database
Return the schema for the orderdsn database.
% ttSchema orderdsn
-- Database is in Oracle type mode
create table TTUSER.CUSTOMER (
CUST_NUM NUMBER(38) NOT NULL,
REGION CHAR(2 BYTE) NOT NULL,
"NAME" VARCHAR2(80 BYTE) INLINE NOT NULL,
ADDRESS VARCHAR2(255 BYTE) NOT INLINE NOT NULL,
primary key (CUST_NUM));
create table TTUSER.ORDERS (
ORD_NUM NUMBER(38) NOT NULL,
CUST_NUM NUMBER(38) NOT NULL,
WHEN_PLACED TIMESTAMP(6) NOT NULL,
WHEN_SHIPPED TIMESTAMP(6),
primary key (ORD_NUM),
foreign key (CUST_NUM) references TTUSER.CUSTOMER (CUST_NUM));
create sequence TTUSER.CUSTID
increment by 1
minvalue 1
maxvalue 1000000
start with 1
cache 20;
create materialized view TTUSER.ORDER_SUMMERY as
SELECT CUST.NAME "NAME", ORD.ORD_NUM "ORD_NUM", COUNT(*) "ORD_COUNT"
FROM TTUSER.ORDERS ORD, TTUSER.CUSTOMER CUST WHERE ORD.CUST_NUM =
CUST.CUST_NUM GROUP BY CUST.NAME, ORD.ORD_NUM ;
Example 3-5 Listing specific objects
Return only the materialized views and sequences for the orderdsn database.
% ttSchema -list views,sequences orderdsn
-- Database is in Oracle type mode
create sequence TTUSER.CUSTID
increment by 1
minvalue 1
maxvalue 1000000
start with 1
cache 20;
create materialized view TTUSER.ORDER_SUMMERY as
SELECT CUST.NAME "NAME", ORD.ORD_NUM "ORD_NUM", COUNT(*) "ORD_COUNT"
FROM TTUSER.ORDERS ORD, TTUSER.CUSTOMER CUST WHERE ORD.CUST_NUM =
CUST.CUST_NUM GROUP BY CUST.NAME, ORD.ORD_NUM ;
Example 3-6 Specifying an object
Return the schema information for the orders table in the orderdsn database.
% ttSchema orderdsn ttuser.orders
-- Database is in Oracle type mode
Warning: tables may not be printed in an order that can satisfy foreign key
reference constraints
create table TTUSER.ORDERS (
ORD_NUM NUMBER(38) NOT NULL,
CUST_NUM NUMBER(38) NOT NULL,
WHEN_PLACED TIMESTAMP(6) NOT NULL,
WHEN_SHIPPED TIMESTAMP(6),
primary key (ORD_NUM),
foreign key (CUST_NUM) references TTUSER.CUSTOMER (CUST_NUM));
Example 3-7 Specifying fixed data types
Return the schema information for the orderdsn database, using fixed data type names.
% ttSchema -fixedTypes orderdsn
-- Database is in Oracle type mode
create table TTUSER.CUSTOMER (
CUST_NUM NUMBER(38) NOT NULL,
REGION ORA_CHAR(2 BYTE) NOT NULL,
"NAME" ORA_VARCHAR2(80 BYTE) INLINE NOT NULL,
ADDRESS ORA_VARCHAR2(255 BYTE) NOT INLINE NOT NULL,
primary key (CUST_NUM));
create table TTUSER.ORDERS (
ORD_NUM NUMBER(38) NOT NULL,
CUST_NUM NUMBER(38) NOT NULL,
WHEN_PLACED ORA_TIMESTAMP(6) NOT NULL,
WHEN_SHIPPED ORA_TIMESTAMP(6),
primary key (ORD_NUM),
foreign key (CUST_NUM) references TTUSER.CUSTOMER (CUST_NUM));
create sequence TTUSER.CUSTID
increment by 1
minvalue 1
maxvalue 1000000
start with 1
cache 20;
create materialized view TTUSER.ORDER_SUMMERY as
SELECT CUST.NAME "NAME", ORD.ORD_NUM "ORD_NUM",
COUNT(*) "ORD_COUNT" FROM TTUSER.ORDERS ORD, TTUSER.CUSTOMER CUST
WHERE ORD.CUST_NUM = CUST.CUST_NUM
GROUP BY CUST.NAME, ORD.ORD_NUM ;
The SQL generated does not produce a history of transformations through ALTER statements, nor does it preserve table partitions, although the output gives information on table partitions in the form of SQL comments. The ttSchema utility prints out the partition numbers for the columns that are not in the initial partition. The initial partition is 0, so partition 1 as printed by ttSchema is secondary partition 1, not the initial partition. For more details on partitions, see "Understanding partitions when using ALTER TABLE," in the "ALTER TABLE" section of the Oracle TimesTen In-Memory Database SQL Reference.
The connection attribute PassThrough with a nonzero value is not supported with this utility and returns an error.
Output is not guaranteed to be compatible with DDL recognized by previous releases of TimesTen.
It is recommended that you do not run DDL SQL commands while running ttSchema to avoid lock contention issues for your application.
Estimates the amount of space that a given table, including any views in the database will consume when the table grows to include rows rows. You can use this utility on existing tables or to estimate table sizes when creating tables. If you do not specify an owner, ttSize prints size information for all tables of the given table name. The size information includes space occupied by any indexes defined on the table.
The memory required for varying-length columns is estimated by using the average length of the columns in the current table as the average length of the columns in the final table. If there are no rows in the current table, then ttSize assumes that the average column length is one half the maximum column length.
The memory required for LOB columns is estimated by using the average length of the columns in the current table as the average length of the columns in the final table. When no rows are being inserted into the table, computations do not include LOB columns.
The table is scanned when this utility is called. Avoid the scan of the table by specifying an optional non-NULL frac value, which should be between 0 and 1. The ttSize utility uses this value to estimate the average size of varying-length columns. The maximum size of each varying-length column is multiplied by the frac value to compute the estimated average size of VARBINARY or VARCHAR columns. If the frac option is not specified, the existing rows in the table are scanned and the average length of the varying-length columns in the existing rows is used. If frac is not specified and the table has no rows in it, then frac is assumed to have the value 0.5.
This utility requires no privileges beyond those needed to perform select operations on the specified database objects.
ttSize {-h | -help | -?}
ttSize {-V | -version}
ttSize -tbl [owner.]tableName [-rows rows] [- frac fraction]
{-connStr connection_string | DSN}
ttSize has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Specifies the name of a data source to which ttSize should connect to retrieve table information. |
-frac frac |
Specifies the estimated average fraction of out-of-line VARCHAR or VARBINARY column sizes that will be used. If this option is omitted and the table contains out-of-line variable sized columns, a table scan is done to determine the average sizes. If the table is empty, the fraction is estimated to be 0.5 (50%) filled. |
-h
|
Prints a usage message and exits. |
-tbl [owner.]tableName |
Specifies the name of the table whose definition should be used for size estimation. If the owner is omitted, the login name of the user is tried. If that is not found, the user SYS is used. |
-rows rows |
Specifies the expected number of rows in the table. Space required to store a TimesTen table includes space for the actual data, plus overhead for bookkeeping, dynamic memory allocation and indexes.
TimesTen may consume additional space due to memory fragmentation, temporary space allocated during query execution and space to hold compiled SQL statements. If this option is omitted, the |
-V | -version |
Prints the release number of ttSize and exits. |
To estimate the space required for a table, create the table in TimesTen, populate it with a sample of representative rows, create desired indexes and execute ttSize with those definitions. For example, to estimate the size of the NAMEID table in the data source FixedDs when it grows to 200,000 rows, execute:
ttSize -tbl Nameid -rows 200000 FixedDs Rows = 200000 Total in-line row bytes = 7139428 Total = 7139428
Another method for estimating size requirements and measuring fragmentation is to use the MONITOR table. (See "SYS.MONITOR" in Oracle TimesTen In-Memory Database System Tables and Views Reference.)
LOB columns are treated similar to var-type columns, unless there are no rows being inserted into the table. The average size computation does not include LOB columns in such cases.
The columns PERM_ALLOCATED_SIZE and PERM_IN_USE_SIZE show the currently allocated size of the database (in KB units) and the in-use size of the database. The system updates this information each time a connection is made or released and each time a transaction is committed or rolled back.
This utility is supported only for TimesTen Data Manager DSNs. It is not supported for TimesTen Client DSNs.
The ttStats utility monitors database metrics (statistics, states, and other information) or takes and compares snapshots of metrics. It can perform the following functions.
Monitor and display database performance metrics in real-time, calculating rates of change during each preceding interval.
Collect and store snapshots of metrics to the database then produce reports with values and rates of change from a specified pair of snapshots. (These functions are performed through calls to the TT_STATS PL/SQL package.)
TimesTen gathers metrics from TimesTen system tables, views, and built-in procedures. In reports, this includes information such as a summary of memory usage, connections, and load profile, followed by metrics (as applicable) for SQL statements, transactions, PL/SQL memory, replication, logs and log holds, checkpoints, cache groups, cache grid, latches, locks, XLA, and TimesTen connection attributes. Monitoring displays a smaller set of key data, as shown later in this section.
For client DSNs, use the ttStatsCS version of the utility (UNIX or Windows).
There are three modes of operation:
Monitor mode (default mode): Tracks database performance in real-time by monitoring a pre-determined set of metrics, displays those metrics (primarily those whose values have changed since the last display), and calculates rates of change in the values where appropriate. Information is output to the standard output for display to the user and is not stored to disk.
If the duration or number of iterations is not specified, the monitoring runs until interrupted with Ctrl-C.
Note:
The set of metrics displayed in monitor mode is subject to change, depending on changes to the system tables and built-in procedures from which metrics are gathered.Snapshot mode: Takes a snapshot of metrics, according to the capture level, and stores them to database SYS.SNAPSHOT_XXXX system tables. Once the snapshot is taken, its ID number is displayed to the standard output. The capture level applies only to metrics from SYS.SYSTEMSTATS. For metrics from other sources, the same data are collected regardless of the capture level.
By default, a "typical" set of metrics is collected, which suits most purposes, but you can specify a reduced "basic" set of metrics, all available metrics, or only those metrics from sources other than SYSTEMSTATS.
Report mode: Generates a report from two specified snapshots of metrics. Reports are in HTML format by default, but you can request plain text format. You can specify an output file or display output to the standard output. For those familiar with Oracle Database performance analysis tools, the ttStats reports are similar in nature to Oracle Automatic Workload Repository (AWR) reports.
In monitor mode, the overhead of reading from the database is avoided. In snapshot mode and report mode, the ttStats utility is a convenient front end to the TT_STATS PL/SQL package provided by TimesTen. Refer to "TT_STATS" in Oracle TimesTen In-Memory Database PL/SQL Packages Reference for details on that package.
Notes:
ThettStats utility has the following dependencies and limitations:
Monitor mode requires features added to the SYS.SYSTEMSTATS table in TimesTen release 11.2.2.4.0.
Snapshot and report modes require the TT_STATS PL/SQL package, added in TimesTen release 11.2.2.5.0.
The utility cannot be used if you are connecting to TimesTen through a driver manager.
Snapshots are stored in a several TimesTen SYS.SNAPSHOT_xxxxx system tables. (For reference, these tables are listed in "Tables and views reserved for internal or future use" in Oracle TimesTen In-Memory Database System Tables and Views Reference.)
For information about built-in procedures mentioned, and the data they gather, see Chapter 2, "Built-In Procedures".
Monitor mode: No special privilege is required to run monitor mode, but ADMIN privilege is required for the monitoring information to include data from the ttSQLCmdCacheInfo built-in procedure and transaction_log_api (XLA) table.
Snapshot and report mode: By default, only the instance administrator has privilege to run in snapshot or report mode, due to security restrictions of the TT_STATS PL/SQL package. Any other user, including an ADMIN user, must be granted EXECUTE privilege for the TT_STATS package by the instance administrator or by an ADMIN user, such as in the following example:
GRANT EXECUTE ON SYS.TT_STATS TO scott;
ttStats [-h | -help] ttStats [-V | -version] ttStats [-monitor] [-interval seconds] [-duration seconds] [-iterations count] {DSN | -connStr connectionString} ttStats -snapshot [-level capture_level] [-notes snap_desc] {DSN | -connStr connectionString} ttStats -report [-snap1 snapid1 -snap2 snapid2] [-html | -text] [-outputFile filename] {DSN | -connStr connectionString}
Note:
Specify only one of-monitor, -snapshot, or -report.ttStats has the options:
| Option | Description |
|---|---|
-h
|
Prints the list of options and exits.
Note: This is also the result if nothing is entered on the |
-V
|
Prints the TimesTen release number and exits. |
-monitor |
Run in real-time monitor mode. Monitors a pre-determined set of metrics and repeatedly displays the metrics and rates of change. Unlike in snapshot mode, nothing is stored to the database.
Note: This is the default mode if neither |
-interval seconds |
For monitor mode, this is the time interval between sets of metrics that are displayed, in seconds. The default is 10 seconds. Shorter intervals may negatively impact system performance. |
-duration seconds |
For monitor mode, this is the duration of how long ttStats runs, in seconds. After this duration, the utility exits.
Also see information for the |
-iterations count |
For monitor mode, this is the number of iterations ttStats performs in gathering and displaying metrics. After these iterations, the utility exits.
Note: If you specify both |
-snapshot |
Collect a snapshot of metrics according to the capture level and store the metrics in the database. Once the snapshot is captured, its ID number is displayed.
Notes:
|
-level capture_level |
For snapshot mode, this is the level of metrics to capture. The possible settings are as follows:
Use the same level for any two snapshots to be used in a report. Notes:
|
-notes snap_desc |
For snapshot mode, optionally use this to provide any description or notes for the snapshot, for example to distinguish it from other snapshots. |
-report |
Generate a report from two specified snapshots, in HTML format by default. Use snapshots taken at the same capture level.
Notes:
|
-snap1 snapid1 |
For report mode, this is the snapshot ID of the first snapshot. |
-snap2 snapid2 |
For report mode, this is the snapshot ID of the second snapshot. |
-outputFile filename |
For report mode, optionally specify a file path and name where the report is to be written. If no file is specified, TimesTen writes the to the standard output. |
-html | -text |
For report mode, specify HTML or plain text output format.
Note: It is not necessary to specify |
-connStr connstring
or
|
To specify and connect to the database from which to gather metrics, do one of the following:
See "Specifying Data Source Names to identify TimesTen databases" in Oracle TimesTen In-Memory Database Operations Guide for information about TimesTen DSNs. |
This section provides examples of ttStats monitoring and report output.
Note:
Examples are for illustrative purposes only. Details are subject to change.This section shows sample output from monitor mode.
% ttStats sampledb_1122 Connected to TimesTen Version 11.02.02.0005 TimesTen Cache version 11.2.2.5.0. Waiting for 10 seconds for the next snapshot Description Current Rate/Sec Notes date.2012-Dec-20 16:49:25 -869676175380467200 1 sample #, not rate connections.count 12 db.size.temp_high_water_mark.kb 7153 7 lock.locks_granted.immediate 832 1 log.log_bytes_per_transaction 0 loghold.bookmark.log_force_lsn 0/12027904 loghold.bookmark.log_write_lsn 0/12050944 loghold.checkpoint_hold_lsn 0/12025856 sampledb_1122.ds0 loghold.checkpoint_hold_lsn 0/12023808 sampledb_1122.ds1 stmt.executes.count 44 1 stmt.executes.selects 32 1
Note:
The number following the date and time is a numeric representation of the time of the snapshot and can be ignored.The following command line example specifies that monitoring should stop after two iterations and uses a connection string to set a connection attribute value.
% ttStats -iterations 2 -connStr "DSN=sampledb_1122;PLSQL_MEMORY_ADDRESS=20000000"
The following examples take two snapshots at the default typical level:
% ttStats -snapshot sampledb_1122 Connected to TimesTen Version 11.02.02.0005 TimesTen Cache version 11.2.2.5.0. Snapshot 1 at TYPICAL level was successfully captured. % ttStats -snapshot sampledb_1122 Connected to TimesTen Version 11.02.02.0005 TimesTen Cache version 11.2.2.5.0. Snapshot 2 at TYPICAL level was successfully captured.
The following example creates a report from the snapshots generated in the previous section.
% ttStats -report -outputFile testreport.html -snap1 1 -snap2 2 sampledb_1122 Connected to TimesTen Version 11.02.02.0005 TimesTen Cache version 11.2.2.5.0. Report testreport.html was created.
The rest of this section shows excerpts from tables of metrics that a ttStats report generates. This output was produced using the default HTML format.
Note:
Examples are not shown for SWT cache group metrics, local cache group metrics, dynamic global cache group metrics, grid metrics, or latch metrics.To include latch metrics, you must enable them for the database, using the ttXactAdmin utility as follows:
% ttXactAdmin -latchstats on DSN
Summary Figure 3-1 shows most of a report summary. The summary is good for a quick look at database metrics, with further details provided in the subsequent tables. It includes the following sections:
Memory Usage and Connections: This information includes information about memory usage (the db.size metrics) and connections established (the connections.established metrics), including the number of client/server connections and direct connections. Any nonzero value for connections.established.threshold_exceeded, indicates too many connections.
Load Profile: This gives an idea of the workload, showing the number of checkpoints, sorts (such as for ORDER BY statements), log buffer waits (delays when the log buffer fills and flushes to disk), inserts, updates, deletes, parses (such as for prepares), commits, and rollbacks. Consider whether there may be too many parses or too many durable commits (which are more expensive than non-durable commits).
Instance Efficiency Percentage: Command Cache Hit %, Non-Parse/Execs %, Lock Hit %, and Log Buffer No Wait % are shown. All should be near 100%.
Lock Hit % estimates the percentage of lock requests that are granted without waiting.
Non-Parse/Execs % represents the percentage of SQL statement executions that do not require a prepare or reprepare.
Command Cache Hit % estimates the percentage of executions of SQL commands that can be found in the command cache.
Log Buffer No Wait % estimates the percentage of log insertions that do not have to wait due to log buffer waits.
Statement statistics Figure 3-2 shows statement metrics from a report. Both external metrics (stmt.executes, stmt.prepares, and stmt.reprepares metrics) and internal metrics (zzinternal metrics) are shown. External metrics are generally of more interest. The stmt.executes.count value is the sum of all the other stmt.executes values.
Figure 3-2 ttStats report: statement statistics
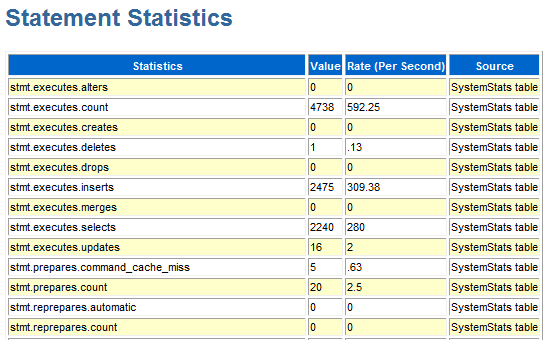
Transaction statistics Figure 3-3 shows transaction metrics from a report. The txn.commits.count value is the sum of the txn.commits.durable and txn.commits.nondurable values. Other metrics shown are subsets of these metrics.
Figure 3-3 ttStats report: transaction statistics
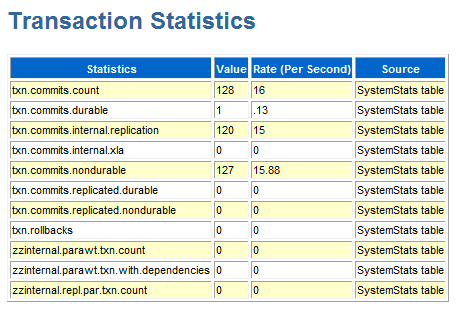
SQL statistics: sort by executions Figure 3-4 shows an excerpt of SQL execution metrics from the SQL Statistics section of a report. When you look at the "sort by executions" metrics and "sort by preparations" metrics (shown in the next section), note which statements are used a lot and the number of preparations and the number of executions for each statement. Ideally, a statement is not prepared many times.
Figure 3-4 ttStats report: SQL execution statistics
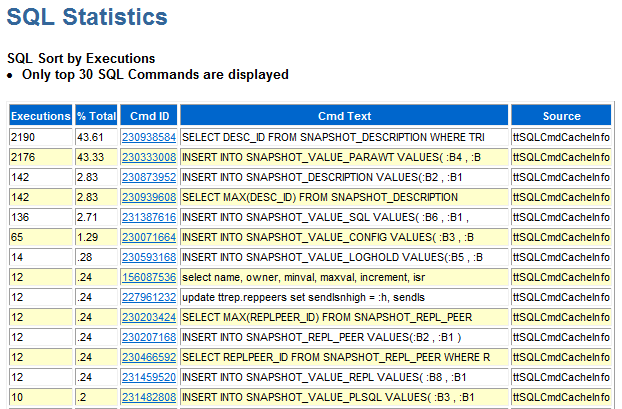
SQL statistics: sort by preparations Figure 3-5 shows an excerpt of SQL preparation metrics from the SQL Statistics section of a report. Refer to the discussion in the preceding "sort by executions" section.
Figure 3-5 ttStats report: SQL preparation statistics
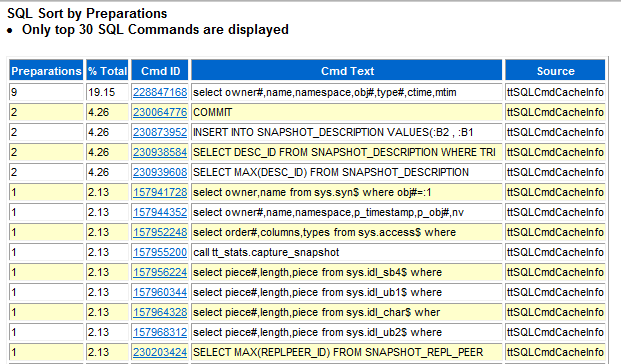
SQL statistics: command texts Figure 3-6 shows an excerpt of SQL statements from the SQL Statistics section of a report. This report shows the complete text of each statement listed in the preceding "sort by executions" and "sort by preparations" reports, where longer statements are abbreviated.
Figure 3-6 ttStats report: SQL command texts
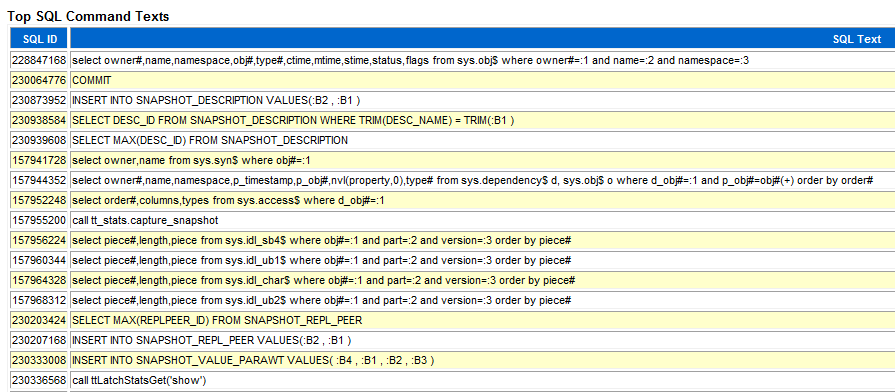
PL/SQL memory statistics Figure 3-7 shows PL/SQL memory metrics from a report. These are metrics from the ttPLSQLMemoryStats built-in procedure. There should not be a significant difference between the start and end values of GetHitRatio or PinHitRatio.
Figure 3-7 ttStats report: PL/SQL memory statistics
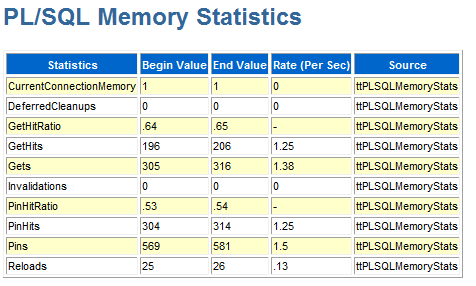
Replication statistics Figure 3-8 shows replication metrics from a report. For each transmitter (where there could be multiple transmitters per master), the metrics indicate advancement through the log, including how many records were sent to the receiver. Repl_Peer indicates the subscriber. Repl_Log_Behind and Repl_Latency are significant in indicating whether replication is keeping up with the database workload.
Figure 3-8 ttStats report: replication statistics
Parallel replication/AWT statistics Figure 3-9 shows an excerpt of parallel replication/AWT metrics from a report. Repl_Peer indicates the subscriber. When parallel replication/AWT is configured, if replication metrics (discussed in the previous section) indicate difficulty keeping up with the workload, parallel replication/AWT metrics may indicate why. Each value is an aggregate across all tracks, but you can click Show Details (at the end of the metrics table, not shown here) to see the data for each track. High values for track switching—"switchin" and "switchout" metrics—may indicate contention. High values for "waits" metrics are also problematic, indicating situations such as one transaction having to wait for a previous transaction to commit before it can begin or before it can commit.
Figure 3-9 ttStats report: parallel replication/AWT statistics
Log statistics Figure 3-10 shows log metrics from a report. The report output notes that numbers in log.file.earliest and log.file.latest represent values in the begin and end snapshots. The log.buffer.waits metric is of particular interest. Log buffer waits occur when application processes cannot insert transaction data to the log buffer and must stall to wait for log buffer space to be freed. The usual reason for this is that the log flusher thread has not cleared out data fast enough. This may indicate that log buffer space is insufficient, disk bandwidth is insufficient, writing to disk is taking too long, or the log flusher is CPU-bound. (Also see "Managing transaction log buffers and files" and "Increase LogBufMB if needed" in Oracle TimesTen In-Memory Database Operations Guide.)
Figure 3-10 ttStats report: log statistics
Log holds Figure 3-11 shows log hold information from a report. It shows bookmark positions for checkpoint log holds for each checkpoint file, and bookmark positions for replication log holds for each replication subscriber. This report may also show log hold information for backup, XLA, and long-running transactions. Where the begin and end values are the same, there have been no movements.
Ideally there will be evidence of a smooth progression through the log file. (The ttStats monitor information may be more useful in tracking this.)
Checkpoint statistics Figure 3-12 shows checkpoint metrics from a report.
Figure 3-12 ttStats report: checkpoint statistics
Cache group statistics: AWT cache groups Figure 3-13 shows AWT cache group metrics from a report. Values are aggregates across all AWT cache groups. Information includes the number of calls to the Oracle database; the number of commits, rollbacks, and retries on Oracle; and the number of rows inserted, deleted, and updated by PL/SQL operations and by SQL operations.
Figure 3-13 ttStats report: AWT cache group statistics
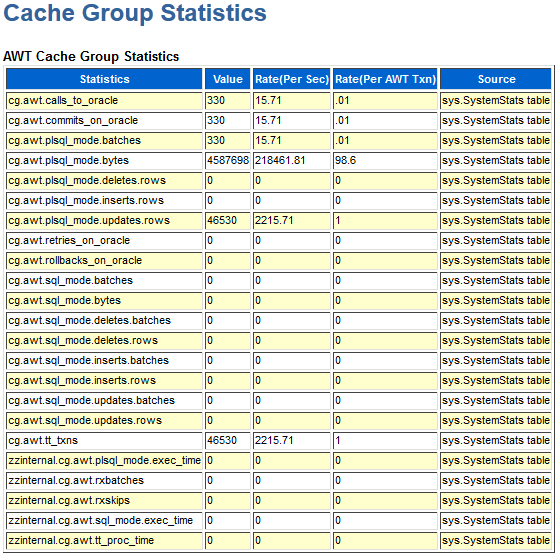
Cache group statistics: auto-refresh cache groups Figure 3-14 shows auto-refresh cache group metrics from a report. Values are aggregates across all auto-refresh cache groups. Whether cache groups are in full or incremental refresh mode is reflected by the cg.autorefresh.full_refreshes value with respect to the cg.autorefresh.cycles.completed value (which indicates the total number of refreshes).
Figure 3-14 ttStats report: auto-refresh cache group statistics
Database activity statistics Figure 3-15 shows an excerpt of database activity metrics from a report—index activity, memory activity, and table activity. For hash indexes and range indexes, information includes deletes, inserts, rows fetched, and scans. For memory usage, it shows size data. For tables, it shows rows read, deleted, inserted, and updated.
Figure 3-15 ttStats report: database activity statistics
Lock statistics Figure 3-16 shows lock metrics from a report. This provides information about deadlocks, locks acquired, locks granted, and lock timeouts. In particular, lock.deadlocks, lock.locks_granted.wait, and lock.timeouts may indicate lock contention.
Figure 3-16 ttStats report: lock statistics
XLA information Figure 3-17 shows XLA bookmark information from a report. For each bookmark, the begin and end values are shown for Purge_LSN, which indicates the position in the log file prior to which information has been purged, and for Log_Behind, which indicates whether there is a lag between the position of the XLA transaction and the position of the most recent log file.
Figure 3-17 ttStats report: XLA information

Configuration parameters Figure 3-18 shows database configuration parameter settings from a report. For reference, each report shows the begin and end values of each TimesTen connection attribute.
For information about connection attributes, see Chapter 1, "Connection Attributes".
Figure 3-18 ttStats report: configuration parameters
Displays information that describes the current state of TimesTen. The command displays:
State of the TimesTen daemon process and all subdaemon processes.
Names of all existing TimesTen databases.
Number of connections currently connected to each TimesTen database.
The RAM, cache agent and replication policies.
TimesTen cache agent status.
The status of PL/SQL.
The key and address of the shared memory segment used by TimesTen.
The address, key and ID of the shared memory segment used by PL/SQL.
Whether the TimesTen instance is accessible by a specified operating system group or accessible by anyone. For more details, see the daemon options in the "Managing TimesTen daemon options" in Oracle TimesTen In-Memory Database Operations Guide.
Miscellaneous status information.
If you specify a connection string or DSN, ttStatus outputs only the information for the specified database.
ttStatus {-h | -help | -?}
ttStatus {-V | -version}
ttStatus [-v] [-r secs] [-[no]pretty]
ttStatus [-r secs] [-[no]pretty] {DSN | -connStr connection_string | dspath}
ttStatus has the options:
| Option | Description |
|---|---|
-h
|
Prints a usage message and exits. |
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Indicates the ODBC data source name of the database for which to get a status. |
-dsn DSN |
Specifies the DSN for which you want status. If no DSN is specified, shows the status of all connections to the data store. |
-[no]pretty |
With [no], indicates that pretty formatting is not used. The default is pretty formatting, which uses the values of the ConnectionName connection attribute. |
-r secs |
Enables ttStatus to continue running. Updates status report every secs seconds. |
-V | -version |
Prints the release number of ttStatus and exits. |
-v |
Prints detailed information that is useful for TimesTen customer support. |
When you call the procedure, a report that describes the current state of the system is displayed to stdout. To get the status for the cachedb1_1122 DSN, use the following:
ttstatus cachedb1_1122
TimesTen status report as of Thu May 02 19:45:43 2013 Daemon pid 5280 port 53392 instance tt1122_32 TimesTen server pid 3940 started on port 53393 ------------------------------------------------------------------------ Data store cachedb1_1122 There are 12 connections to the data store Shared Memory KEY Global\cachedb1_1122.c|. . .HANDLE 0x254 PL/SQL Memory KEY Global\cachedb1_1122.c|. . . HANDLE 0x258 Address 0x5B8C0000 Type PID Context Connection Name ConnID Process 5196 0x01066a58 cachedb1_1122 1 Subdaemon 3912 0x00b2c398 Manager 2047 Subdaemon 3912 0x00b7e4a0 Rollback 2046 Subdaemon 3912 0x015d25e8 Flusher 2045 Subdaemon 3912 0x015e46b0 Monitor 2044 Subdaemon 3912 0x016767f8 Deadlock Detector 2043 Subdaemon 3912 0x016888c0 Checkpoint 2041 Subdaemon 3912 0x0d350578 Aging 2042 Subdaemon 3912 0x0d362640 Log Marker 2040 Subdaemon 3912 0x0d4347c8 AsyncMV 2039 Subdaemon 3912 0x0d446890 HistGC 2038 Subdaemon 3912 0x0d458958 IndexGC 2037 Replication policy : Manual Cache Agent policy : Manual PL/SQL enabled. ------------------------------------------------------------------------ Accessible by group . . . End of report
While primarily intended for use by TimesTen customer support, this information may be useful to system administrators and developers.
This utility is supported only where the TimesTen Data Manager is installed.
The ttStatus utility only reports the RAM policy if it is not inUse.
Determines if the system's /etc/syslog.conf file is properly configured for TimesTen. The TimesTen Data Manager uses syslog to log a variety of progress messages. It is highly desirable to configure syslog so that TimesTen writes all messages to disk in a single disk file. The ttSyslogCheck utility examines the syslog configuration (in /etc/syslog.conf) to verify that it is properly configured for TimesTen.
If syslog is properly configured, ttSyslogCheck displays the name of the file that TimesTen messages are logged to and exits with exit code 0. If syslog is not properly configured, ttSyslogCheck displays an error message and exits with code 1.
ttSyslogCheck has the options:
| Option | Description |
|---|---|
-h
|
Prints a usage message and exits. |
-facility name |
Specifies the syslog facility name being used for message logging. |
-V | -version |
Prints the release number of ttSyslogCheck and exits. |
Fetches TimesTen internal trace information from a database and displays it to stdout. By default, TimesTen generates no tracing information. See "ttTraceMon" for more information.
ttTail {-h | -help | -?}
ttTail {-V | -version}
ttTail [-f] {-connStr connection_string | DSN}
The ttTail utility supports the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Indicates the ODBC data source name of the database from which to get a trace. |
-f |
When the end of the trace is reached, ttTail does not terminate but continues to execute, periodically polling the database's trace buffer to retrieve and display additional TimesTen trace records. For example, this is useful for generating a display of trace data that is updated in real time. |
-h-help
|
Prints a usage message and exits. |
-V | -version |
Prints the release number of ttTail and exits. |
The ttTraceMon utility lets you enable and disable the TimesTen internal tracing facilities.
Tracing options can be enabled and disabled separately for each database. Each database contains a trace buffer into which messages describing TimesTen internal operations can be written. By default, tracing is disabled. However, it can be enabled using this utility.
The ttTraceMon utility provides subcommands to enable, disable, dump and manipulate trace information. ttTraceMon can be executed interactively (multiple subcommands can be entered at a prompt) or not interactively (one subcommand can be specified on the ttTraceMon command line).
When executed interactively, ttTraceMon prompts for lines of text from standard input and interprets the lines as trace commands. You can provide multiple trace commands on the same line by separating them with semicolons. To exit ttTraceMon, enter a blank line.
In interactive mode, you can redirect ttTraceMon command output to a file:
ttTraceMon connection_string >filename
Component names are case-insensitive. Some commands (dump, show and flush) allow you to list many components and operate on each one. For each subcommand, if you do not list components, the utility operates on all components.
For a description of the components available through this utility and a description of the information that ttTraceMon returns for each, see "Using the ttTraceMon utility" in Oracle TimesTen In-Memory Database Troubleshooting Guide.
ttTraceMon {-h | -help | -?}
ttTraceMon {-V | -version}
ttTraceMon [-e subcommand] {-connStr connection_string | DSN}
ttTraceMon has the options:
| Option | Description |
|---|---|
-connStr connection_string |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
Indicates the ODBC data source name of the database from which to get trace information. |
-e subcommand |
Causes the subcommand to be executed against the specified database. If the subcommand consists of more than one word, enclose it in double quotes. For example:
ttTraceMon -e "show err" SalesData Once the subcommand is complete, |
-h
|
Prints a usage message and exits. |
-V | -version |
Prints the release number of ttTraceMon and exits. |
ttTraceMon can be called with the following subcommands:
| Command | Description |
|---|---|
components |
List the names and internal identifiers of all components.
For a description of the components available through this utility and a description of the information that |
connection {all | self | connectionNum} [on |off] |
Turn tracing on/off for specified connection. At database creation, tracing is "on" for all connections. The value for connectionNum is the connection slot number or the first number in the transaction ID. |
dump |
Prints all trace records currently buffered.Requires SELECT privileges or database object ownership. |
dump comp |
Prints all trace records for component comp.Requires SELECT privileges or database object ownership. |
flush |
Discards all buffered trace records. |
flush comp |
Discards all buffered trace records for component comp. |
help |
Prints a summary of the trace commands. |
level comp n |
Sets the trace level for component comp to n.Requires ADMIN privileges or database object ownership. |
outfile file |
Prints trace output to the specified file. The file may be any of 0, stdout, stderr, or a file name. On Windows, the file name must be in short 8.3 format. Printing is turned off when file is 0. TimesTen continues to buffer traces as usual, and they are accessible through other utilities like ttTail. If no file is specified, prints the current outfile setting. |
show |
Shows all the trace levels in force. |
show comp |
Shows the trace level for component comp. |
Because tracing can degrade performance significantly, we recommend that you enable tracing only to debug problems. While primarily intended for use by TimesTen customer support, this information may be useful to system administrators and developers.
This utility is supported only where the TimesTen Data Manager is installed.
Prompts for a password and returns an encrypted password. You can then include the output in a connection string or as the value for the PWDCrypt connection attribute in an ODBCINI file.
The ttVersion utility lists the TimesTen release information, including: number, platform, instance name, instance administrator, instance home directory, daemon home directory, port number and build timestamp. You can specify various levels of output:
You can specify ttVersion with no options to list abbreviated output.
You can specify the -m option to list enhanced output.
You can specify an attribute to list output only for a specific attribute.
ttVersion has the option:
| Option | Description |
|---|---|
-m |
Generates computer-readable enhanced output. If not specified and no attribute is specified, abbreviated information is output. |
attribute |
Generates information only about the specified attribute. You can specify multiple attributes. When you specify more than one attribute, the output is displayed with an equal sign after the attribute name. |
ttVersion has these attributes:
| Attribute | Description |
|---|---|
patched |
Lists yes or no, indicating whether the release has been patched. |
product |
Lists the name of the product. |
major1 |
The first number of the five-place release number. |
major2 |
The second number of the five-place release number. |
major3 |
The third number of the five-place release number. |
patch |
The fourth number of the five-place release number. |
portpatch |
The fifth number of the five-place release number. |
version |
All five numbers of the release number, separated by periods. |
shortversion |
The first three numbers of the five-place release number. |
numversion |
The first four numbers of the five-place release number, represented by three digits for each place. |
bits |
Lists 32 or 64 to indicate the bit-level of the operating system for which this release is intended. |
os |
The operating system for which this release is intended |
buildstamp |
A number indicating the specific build. |
buildtime |
The UTC time the release was built, for example: 2013-03-19T17:21:59Z |
clientonly |
Lists yes or no to indicate if the release is a client-only release |
instance |
The name of the instance, for example: tt1122_32. |
effective_port |
The number of the port on which the main daemon listens. |
orig_port |
The original number of the port on which the main daemon listened. |
instance_admin |
The user name of the instance administrator. |
effective_insthome |
The path that indicates the location of the instance. |
effective_insthome_long |
On Windows, the path that indicates the location of the instance including a bit extension on the instance name. |
orig_insthome |
The path that indicates the location of the instance. |
effective_daemonhome |
The path to the home of the daemon for the specific instance. |
effective_daemonhome_long |
On Windows, the path to the home of the daemon for the specific instance, including a bit extension on the instance name. |
orig_daemonhome |
The path to the original home of the daemon. |
plsql |
Indicates if PL/SQL is configured for this instance. 0 indicates that PL/SQL is not configured. 1 indicates that PL/SQL is configured. The value corresponds with the setting of the PLSQL connection attribute. |
group_name |
The name of the instance group. |
ttVersion produces the following sample output.
TimesTen Release 11.2.2 (32 bit Linux/x86) (tt1122_32:53384) 2013-03-26T23:00:04Z Instance admin: terry Instance home directory: spider/terry/TimesTen/tt1122_32 Daemon home directory: spider/terry/TimesTen/tt1122_32/srv/info
ttVersion -m produces the following sample output. Most of the entries only appear for patch releases.
patched=yes product=TimesTen major1=11 major2=2 major3=2 patch=5 portpatch=0 version=11.2.2.5.0 shortversion=1122 numversion=110200020500 bits=32 os=Linux buildtstamp=1364278134 buildtime=2013-03-26T06:08:54Z clientonly=no instance=tt1122_32 effective_port=53392 orig_port=53392 instance_admin=terry effective_insthome=/spider/terry/ttcur/TTBuild/linux86_dbg/tt1121_32 orig_insthome=/spider/terry/ttcur/TTBuild/linux86_dbg/tt1121_32 effective_daemonhome=/spider/terry/ttcur/TTBuild/linux86_dbg/tt1121_32/info orig_daemonhome=/spider/terry/ttcur/TTBuild/linux86_dbg/tt1121_32/info plsql=0 groupname=timesten
The ttXactAdmin utility lists ownership, status, log and lock information for each outstanding transaction. The ttXactAdmin utility also enables you to heuristically commit, terminate or forget an XA transaction branch.
Applications should monitor log holds and the accumulation of log files. For more information, see "Monitoring accumulation of transaction log files" in the Oracle TimesTen In-Memory Database Operations Guide.
This utility requires various privileges depending on which options are entered on the command line. See the description of the options to determine which privilege is needed, if any.
ttXactAdmin {-h | -help | -?}
ttXactAdmin {-V | -version}
ttXactAdmin [-v verbosity] [-mt maxTrans] [-ml maxLocks] [-pid pid]
[-xact xid] [-tbl [owner.]tableName] [-interval seconds]
[-count iterations] {DSN | -connstr connectionString}
ttXactAdmin -latch [-interval seconds] [-count iterations]
{DSN | -connstr connStr}
ttXactAdmin -latchstats clear | off |on | [show] [-interval seconds]
[-count iterations] {DSN | -connstr connectionString}
ttXactAdmin -connections [-pid pid] [-interval seconds]
[-count iterations] {DSN | -connstr connStr}
ttXactAdmin -xactIdRollback xid {DSN | -connstr connStr}
ttXactAdmin {-HCommit xid | -HAbort xid | -HForget xid} {DSN | -connstr connStr}
ttXactAdmin has the options:
| Option | Description |
|---|---|
-connections |
Shows all current connections to the database. When run with the -connections option, ttXactAdmin itself does not establish a true connection to the database, and requires no latches. This can be useful when diagnosing frozen systems.
This option requires |
-connStr connectionString |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
-count iterations |
Generate the report iterations times. If no-interval option is specified, an interval of 1 second is used. |
DSN |
Indicates the ODBC data source name of the database to be administered.
This option requires |
-h
|
Prints a usage message and exits. |
-HAbort xid |
Heuristically terminates an XA transaction branch in TimesTen. The specified transaction ID must be the local TimesTen TransID.
This option requires |
-HCommit xid |
Heuristically commit an XA transaction branch in TimesTen. The specified transaction ID must be the local TimesTen TransID.
This option requires |
-HForget xid |
Heuristically forget an XA transaction branch in TimesTen. The specified transaction ID must be the local TimesTen TransID.
This option requires |
-interval seconds |
Repeat the generation of the report, pausing the indicated number of seconds between each generation. If no -count option is specified, repeat forever. |
-latch |
This option is to be used by TimesTen Customer Support only. Shows only the latch information for the database specified. |
-latchstats[clear | off | on | show] |
This option is to be used by TimesTen Customer Support only. Performs the requested latchstat operation.
This option requires All other options are ignored when
|
-ml maxLocks |
Maximum number of locks per transaction. Default is 6000. |
-mt maxTrans |
Specifies the maximum number of transactions to be displayed. The default is all outstanding transactions. |
-pid pid |
Displays only transactions started by the process with the specified pid. On Linux, it is the pid of the thread that opens the connection.
This option requires |
-row rowid |
Displays lock information for the specified row.
This option requires |
-tbl [owner.]tableName |
Displays lock information for the specified table.
This option requires |
-V | -version |
Prints the release number of ttXactAdmin and exits. |
-v verbosity |
Specifies the verbosity level. One of:
|
-xact xid |
Displays information for the specified transaction, including its log hold LSN.In the output, the field "Last ID" is a set of two sequence numbers. If the sequence numbers did not change in an interval, then no log record was written by the transaction during that interval.
This option requires |
-xactIdRollback xid |
Enables you to roll back a transaction. This may be particularly useful for long running transactions. The parameter xid represents the transaction ID.This stops any currently executing operations on behalf of that transaction and then rolls back the transaction in TimesTen.
If there is currently a checkpoint in process when the rollback is requested, TimesTen terminates the checkpoint operation.This command does not stop TimesTen Cache operations on the Oracle database. Operations include passthrough statements, flushing, manual loading, manual refreshing, synchronous writethrough, propagating, and dynamic loading. This option requires |
ttXactAdmin produces the following output:
| Column | Description |
|---|---|
Program File Name |
The executable file name of the process that owns the transaction. |
PID |
The process ID of the application that owns the transaction. On Linux, the PID of the thread that opens the connection. |
Context |
The internal identifier that distinguishes between multiple connections to the database made by a single multithreaded process. |
TransId |
The unique identifier for the transaction used internally by TimesTen. The identifier has two parts.
The first part is a relatively small value (less than 2048), used to identify the connection of the program executing the transaction. The second part is a potentially large value (an unsigned integer), that distinguishes between successive uses of the same first part. (The value wraps around if necessary.) Thus, identifiers 4.100 and 4.200 cannot be present at the same time. If 4.100 is seen, and then 4.200, this indicates that transaction 4.100 has completed (committed or rolled back). |
TransStatus |
Current status of the transaction, one of:
|
Resource |
The type of the lock being requested:
|
ResourceId |
A unique identifier of each unique resource. The identifier is displayed in hexadecimal format with a few exception. Table and CompCmd are shown as decimal values. Row locks are shown in the ROWID character format. |
Mode |
A value used to determine the level of concurrency that the lock provides:
|
HMode |
The mode in which the competing transaction is holding the lock which the waiting transaction is requesting.
See "Mode" in this table for concurrency level descriptions. |
RMode |
Shows the mode in which the waiting transaction has requested to hold the lock. See "Mode" in this table for concurrency level descriptions. |
HolderTransId |
The identifier of the transaction with which the waiting transaction is in contention. |
Name |
The name of the table that the lock is being held on or within. |
The following command displays all locks in the database:
ttXactAdmin -connstr DSN=demodata Outstanding locks
PID Context TransId TransStatus Resource ResourceId Mode Name
Program File Name: localtest
10546 0x118e28 2047.000003 Active Table 411104 IS SYS.TABLES
Table 416480 IXn TEST1.TAB1
Row BMUFVUAAABQAAAAGTD Sn SYS.TABLES
Hashed Key 0x69cf9c36 Sn SYS.TABLES
Database 0x01312d00 IX
Row BMUFVUAAABQAAAAGzD Xn TEST1.TAB1
Program File Name: /users/smith/demo/XAtest1
XA-XID: 0xbea1-001b238716dc35a7425-64280531947e1657380c5b8d
1817 0x118e28 2046.000004 Active Table 416480 IS TEST1.TAB1
CompCmd 21662408 S
Database 20000000 IS
Row BMUFVUAAABQAAAAJzD Sn TEST1.TAB1
Program File Name: /users/smith/demo/XAtest2
XA-XID: 0xbea1-001c99476cf9b21e85e1-70657473746f7265506f6f6c
27317 0x118e28 2045.000005 Prepared Table 411104 IS SYS.TABLES
Table 416816 IXn TEST1.TAB2
Row BMUFVUAAABQAAAAMzD Sn SYS.TABLES
Database 0x01312d00 IX
Hashed Key 0x67fe3852 Sn SYS.TABLES
Row BMUFVUAAABQAAAAHTE Xn TEST1.TAB2
Program File Name: /users/smith/demo/Reptest
27589 0x118e28 2044.000006 Rep-Wait-Return
Awaiting locks
PID Context TransId Resource ResourceId RMode HolderTransId HMode Name
Program File Name: /users/smith/demo/XAtest1
1817 0x118e28 2046.000004 Row BMUFVUAAABQAAAAPTD Sn 2047.000003 Xn TEST1.TAB1
The following command displays all locks for transaction 2045.000005:
ttXactAdmin -xact 2045.000005 -connstr DSN=demodata
PID Context TransStatus 1stLSN LastLSN Resource ResourceId Mode Name
Program File Name: /users/smith/demo/XAtest2
XA-XID: 0xbea1-001c99476cf9b21e85e1-70657473746f7265506f6f6c
27317 0x118e28 Prepared 0.0116404 0.0116452 Table 411104 IS SYS.TABLES
Table 416816 IXn TEST1.TAB2
Row BMUFVUAAABQAAAAGzE Sn SYS.TABLES
Database 0x01312d00 IXn
Hashed Key 0x67fe3852 Sn SYS.TABLES
Row BMUFVUAAABQAAAAKzE Xn TEST1.TAB2
To display all the connections to the database:
$ ttXactAdmin -connections sample
2006-09-10 10:26:33
/datastore/terry/sample
TimesTen Release 11.2.2.0.0
ID PID Context Name Program State TransID UID
1 29508 0x00000001001c6680 myconnection ttIsql Run 1.23 TERRY
2044 29505 0x0000000100165290 Worker timestensubd Run TERRY
2045 29505 0x00000001001df190 Flusher timestensubd Run TERRY
2046 29505 0x000000010021cc50 Monitor timestensubd Run TERRY
2047 29505 0x0000000100206730 Checkpoint timestensubd Run TERRY
5 connections found
If the transaction specified in the command is not an XA transaction branch but a TimesTen local transaction, no XA-XID are displayed. The XA-XID is a C structure that contains a format identifier, two length fields and a data field. The data field consists of at most two contiguous components: a global transaction identifier (gtrid) and a branch qualifier (bqual). The two length fields specify the number of bytes (1-64) in gtrid and bqual respectively. For more details, refer to the X/Open publication: Distributed Transaction Processing: The XA Specification (c193).
For databases, TimesTen only holds S locks when the isolation mode is serializable. For commands, S only means "shared" lock, and can be held in either serializable or read-committed isolation modes.Under RMode, awaiting transactions are sorted by PID and Context. The listing does not reflect the order of the lock requests.
A lock request with an RMode compatible with the HMode of the lock holder can be waiting because there is another lock request with an incompatible mode ahead of the compatible request in the lock request queue.
A transaction can have the status Aborting for one of these reasons:
A user application requested rollback after doing a large amount of work.
An application with autocommit tried a statement that could not be completed and it is being undone.
Another call to ttXactAdmin caused a transaction to rollback.
A process died with work in progress and that work is being undone.
Displays a formatted dump of the contents of a TimesTen transaction log. It is designed to be used by TimesTen customer support to diagnose problems in the log or database.
A loss of data can occur with certain options such as -tr, therefore only use this tool if you have been asked to do so by a TimesTen customer support representative.
ttXactLog {-h | -help | -?}
ttXactLog {-V | -version}
ttXactLog [-v verbosity] [-m maxChars] [-s] [-t] [-b blkID]
[-l1 lfn.lfo [-l2 lfn.lfo]] [-r recType] [...] [-tr dir]
[-lb] [-headers recs] [-logdir dir]
{-connStr connection_string | DSN | dspath}
ttXactLog [-v verbosity] -logAnalyze
[-s subscriberName -host hostname]]
[-xid xid] {-connStr connection_string | DSN | dspath}
ttXactLog has the options:
| Option | Description |
|---|---|
-b blkID |
Restricts log records to those accessing this block, plus any transaction records. |
-connStr connectionString |
An ODBC connection string containing the name of the database, the server name and DSN (if necessary) and any relevant connection attributes. |
DSN |
The ODBC source name of the database for which to display the transaction log. |
dspath |
The fully qualified name of the database. This is not the DSN associated with the connection but the fully qualified database path name associated with the database as specified in the DataStore= parameter of the database's ODBC definition.
For example, for a database consisting of files |
-h
|
Prints a usage message and exits. |
-headers records |
Prints one header for every records records. A value of 0 disables headers. |
-host hostName |
Specifies the name of the host on which the subscriber resides. Use this option with the -subscriber option, if the name of the subscriber is ambiguous. |
-lb |
Connects to the database and prints out the log buffer. Contents of the transaction log files are not printed. Requires SELECT privileges or database object ownership. |
lfn.lfo |
Transaction log file number (lfn) and transaction log file offset (lfo) for a log record. |
-l1 |
Considers this log record only (unless an -l2 argument is present). |
-l2 |
Considers records between -l1 and -l2, inclusive. |
-logAnalyze |
Determines the remaining amount of a database to be replicated for one or all of the subscribers.Use with the -v option to print:
Use with |
-logdir dir |
Specifies |
-m maxChars |
Maximum number of characters printed for binary items (for -v 3) only (defaults to 4000). |
-r recType |
Considers only records of the specified type. This option may be used multiple times to specify a list of desired log record types. recType is case-sensitive. |
-s |
Prints summary information. Requires SELECT privileges or database object ownership. |
-subscriber subscriberName |
Specifies the name of the subscriber. To qualify the name of the subscriber, use -host hostname. |
-t |
Only reads transaction log file tail (from start of last checkpoint transaction log file or, if no checkpoint, the most recent transaction log file). |
-tr dir |
Truncates all log records in the directory at the LWN boundary. The original transaction log files are moved to the directory dir. |
-V | -version |
Prints the release number of ttXactLog and exits. |
-v verbosity |
Specifies the verbosity level. One of:
|
-x xid |
Specifies the transaction ID. |
|
Copyright © 2014, Oracle and/or its affiliates. All rights reserved. Legal Notices |
|